File tools and validate: the agent's feedback loop
What this post covers
This post gives the agent real work. In previous posts we just gave it toy work to make sure the infrastructure, monitoring, and audit logs work. Now we build a harness for the agent to write Terraform and validate it.
To do this we give the agent a few tools:
- Sandboxed File System Tools:
list_files: list files in a folder.read_file: read a file.write_file: write a file.edit_file: edit a file (search and replace based).delete_file: delete a file.
- Terraform Tools:
terraform_init: initialize a Terraform workspace.terraform_validate: validate a Terraform workspace.
The sandboxed file system tools themselves are simple; most of the work is returning good error messages to the model and making sure it does not breach the boundaries of the sandbox tmp folder. The terraform tools on the other hand are more complex, and they have consequences for the Lambda setup. They need to actually execute the terraform binary. For this post that meant changing the Lambda from a Python to a Docker based Lambda, which did require changing the build process and infrastructure setup.
Typical agent flow looks like this:
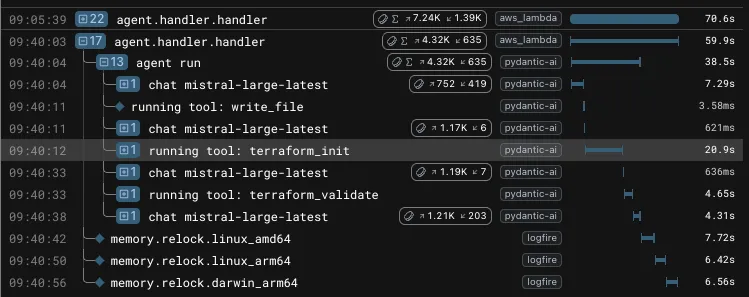
Notice the new AWS Lambda span, which was not there in the previous post. This is because I wanted to extend instrumentation given that now there is more happening than just the agent run. We do also re-lock the terraform dependency lock file for different architectures after the agent run and I wanted to see timings and memory usage for the external terraform process. Because we are using AWS Lambda, memory is a constraint and cost factor, made worse by the fact that if you are (like me) running this in a new sandbox AWS account you are capped at 3008 MB of memory. Increasing that is a slow process on basic support.
The system prompt in this iteration is not optimized (we’ll do that in a later post). We just tell the
agent what tools it has and that it needs to run terraform-init before the first validate. list_files/read_file
is currently not that important as we do not hook up GitHub/existing terraform code in this post. It will be more
important when the agent needs to assess how to integrate its code into an existing project and to follow that project’s
best practice guidelines when doing so.
You are the terraform-pr-agent. You operate on a Terraform workspacethrough file tools (list_files, read_file, write_file, edit_file, delete_file)and two terraform tools. Use the file tools to explore, write, and edit.Run terraform_init before your first validate and again whenever you addor change provider or module requirements. Call terraform_validate afteryou write or change files to confirm the workspace still parses; treat itsoutput as feedback and edit until it is clean.
When you add the AWS provider, give it a version constraint such as "~> 6.0"rather than leaving it unconstrained. terraform init records the exact resolvedversion and checksums in .terraform.lock.hcl, which travels with the workspaceand is the reproducibility record, so the constraint does not need to be an exactpin. Pin an exact version only when the user asks for one. Example:
terraform { required_providers { aws = { source = "hashicorp/aws" version = "~> 6.0" } }}Similarly, the user prompt is basic, with not much thought put into it. It is passed in the invoke event payload.
Set up a new terraform project, creating a best practice s3 bucket.We store the end result in an S3 bucket. With no GitHub integration yet, that is a simple way to inspect the files the agent produced and validate the outcome.
Architecture
Post 2 wrapped the agent in a Lambda and stood up the dual-sink span pipeline behind it; post 3 made the model a
runtime choice (an SSM model registry, a Mistral provider beside Bedrock, and EMF metrics feeding one CloudWatch
dashboard). Post 4 keeps all of that as is. The Lambda itself changes from a zip package to a container image so we can
ship the terraform CLI alongside the Python runtime; a new ECR repository holds the image, and terraform seeds it
with a placeholder so the function can be created before the first real push, the container twin of post 2’s
placeholder zip. Everything else around the function (IAM, Bedrock, the model registry, Firehose, S3) carries forward
unchanged. The rest of the post is software: a workspace under /tmp, file tools, the terraform_validate tool, and
a caller-side retry.
The code
Prerequisites (one-time setup for the series)
Tooling and AWS access common to every post in this series.
Tooling
- Terraform 1.x (install). Every post provisions infrastructure with Terraform.
- uv for Python project management (install). Each post ships a runnable script you can invoke with
uv run. - direnv (install) so
terraform,uv run, andawspick up AWS credentials automatically oncd. The project scaffold ships an.envrcthat sources a gitignored.envrc.local. - (Optional) A coding agent such as Claude Code, Cursor, Codex, or Gemini CLI to consume the
AgentPromptblocks throughout the series. Not required (each prompt has a manual equivalent shown alongside it), but it skips the boilerplate.
Agent prompt: Check and install missing tooling
You are helping set up tooling for a tutorial project.
For each of `terraform`, `uv`, and `direnv`, run `command -v` to
check whether it is installed. If present, print the version and
continue.
For missing tools, detect the system package manager in this order:
`command -v brew`, `command -v dnf`, `command -v apt-get`. Use the
first one available:
- Terraform: `brew tap hashicorp/tap && brew install hashicorp/tap/terraform`,
dnf via the HashiCorp RPM repo, or apt via the HashiCorp deb repo.
- uv: `brew install uv`, or the official installer
`curl -LsSf https://astral.sh/uv/install.sh | sh`.
- direnv: `brew install direnv`, `dnf install direnv`, or
`apt-get install direnv`.
If no package manager is available or the install fails, stop and
link the manual install page so the developer can finish by hand:
- Terraform: https://developer.hashicorp.com/terraform/install
- uv: https://docs.astral.sh/uv/getting-started/installation/
- direnv: https://direnv.net/docs/installation.html
After installing direnv, do not modify any shell rc files. Print the
hook line for the developer's shell (bash, zsh, or fish) and the path
to the relevant rc file, then wait for them to apply it themselves.
Report which tools were already present, which you installed, and
which need manual follow-up.
AWS access
- A sandbox, test, or personal AWS account with permission to create, modify, and delete the resources discussed in each post. If you don’t have one, follow the official Create Your AWS Account walkthrough (about ten minutes; requires a credit card and a phone number for verification). Treat it as disposable - you can close it from the billing console after the series.
- AWS credentials available locally via
aws configure sso,aws configure, or whichever method matches your setup. You wire them into the project through.envrc.localin the next section, not your shell rc.
Anthropic First Time Use
Bedrock requires a one-time use-case form per account (or per AWS Organization management account) before Anthropic models can be invoked. Easiest path: open any Claude model in the Bedrock console playground and submit the form. Auto-subscription on first invoke can take up to 15 minutes to settle, so it is worth clearing this before post 1.
CLI alternative and verification
Programmatic equivalent (requires AWS CLI 2.27.42 or later):
aws bedrock put-use-case-for-model-access \ --form-data "$(printf '{"companyName":"...","companyWebsite":"...","intendedUsers":"1","industryOption":"...","otherIndustryOption":"","useCases":"..."}' | base64)"Verify:
aws bedrock get-foundation-model-availability \ --model-id anthropic.claude-haiku-4-5-20251001-v1:0 \ --region eu-west-1Look for agreementAvailability.status: AVAILABLE. Expected output:
{ "modelId": "anthropic.claude-haiku-4-5-20251001-v1", "agreementAvailability": { "status": "AVAILABLE" }, "authorizationStatus": "AUTHORIZED", "entitlementAvailability": "AVAILABLE", "regionAvailability": "AVAILABLE"}If the form has not been submitted, only agreementAvailability.status flips to NOT_AVAILABLE. The other three fields stay green even when invocation would fail, so do not rely on them.
The final tree. + is new in post 4, ~ extends a post 3 file, blank carries unchanged. Click any changed or new file
to read it; the download below fast-forwards to this state if you want to walk through the post against the finished
code. We also split the old handler.py in two: core.py holds the agent and an execute(prompt, model) that knows nothing
about Lambda, and lambda_entry.py is the Lambda boundary that parses the event and calls it. It was getting out of hand
as this post’s functionality piled on.
"""Define the agent and execute one run.
Runtime-agnostic: a fresh /tmp workspace threaded through the file and validatetools, one run id that joins the audit trace, the parked artifacts, and theresult. The telemetry pipeline lives in observability.py, model construction inmodels.py, and run persistence plus the provider re-lock in runs.py; the Lambdaenvelope and INIT wiring live in lambda_entry.py. This module knows nothingabout Lambda events."""
from __future__ import annotations
import uuidfrom pathlib import Pathfrom tempfile import TemporaryDirectory
from pydantic import BaseModel, ConfigDictfrom pydantic_ai import Agent
from agent.env import require_envfrom agent.models import _build_modelfrom agent.runs import _persist_run, _relock_providersfrom agent.tools import ( WorkspaceDeps, _validate, delete_file, edit_file, list_files, read_file, terraform_init, terraform_validate, write_file,)
# A soft reproducibility nudge following the standard Terraform pattern: a# version constraint in the config, the exact version and checksums in the lock# file. The tool-call spans in the trace are the ground truth for what the agent# actually wrote._PROVIDER_PIN_RULE = ( "When you add the AWS provider, give it a version constraint such as " '"~> 6.0" rather than leaving it unconstrained. terraform init records ' "the exact resolved version and checksums in .terraform.lock.hcl, " "which travels with the workspace and is the reproducibility record, " "so the constraint does not need to be an exact pin. Pin an exact " "version only when the user asks for one. Example:\n" "\n" "terraform {\n" " required_providers {\n" " aws = {\n" ' source = "hashicorp/aws"\n' ' version = "~> 6.0"\n' " }\n" " }\n" "}")
SYSTEM_PROMPT = ( "You are the terraform-pr-agent. You operate on a Terraform workspace " "through file tools (list_files, read_file, write_file, edit_file, " "delete_file) and two terraform tools. Use the file tools to explore, " "write, and edit. Run terraform_init before your first validate and " "again whenever you add or change provider or module requirements. " "Call terraform_validate after you write or change files to confirm " "the workspace still parses; treat its output as feedback and edit " "until it is clean.\n\n" + _PROVIDER_PIN_RULE)
# One Agent instance is reused across invocations: the tools reach the workspace# through RunContext.deps, so each run_sync scopes them to a fresh WorkspaceDeps.# The model carries no default; it is built from the registry at INVOKE and# passed per run, so switching DEFAULT_MODEL needs no code change.agent = Agent( deps_type=WorkspaceDeps, system_prompt=SYSTEM_PROMPT, tools=[ list_files, read_file, write_file, edit_file, delete_file, terraform_init, terraform_validate, ], # Tools raise ModelRetry on failure; pydantic-ai ends the run once one tool # fails more than `retries` times in a row (a success resets the count). The # default of 1 would end the run on the second straight failing validate, # which is a normal part of the write-validate-edit loop, so the budget is # raised well past anything a converging run produces. The per-run turn cap # stays the runaway guard. retries=10,)
# Caller-side backstop budget: how many follow-up runs to spend trying to get a# clean validate after the agent reports done. The per-tool `retries` above# guards the loop inside one run; this guards the run as a whole._MAX_VALIDATE_RETRIES = 3
_RETRY_PROMPT = ( "terraform validate still reports errors after you finished. " "Fix them and validate again.\n\n{output}")
class ValidateDidNotConverge(RuntimeError): """terraform validate still failed after the caller-side retry budget."""
class RunResult(BaseModel): model_config = ConfigDict(frozen=True)
run_id: str model: str output: str
def execute(prompt: str, model: str | None = None) -> RunResult: """Run the agent once and return the result.
The run id is the trace's gen_ai.conversation.id and the runs/<run_id>/ prefix, so one identifier joins trace, artifacts, and result. After the run the caller re-validates the workspace and feeds any failure back as a follow-up turn; a run that still fails after the retry budget raises, so the workspace ships under status error for debugging. ``model`` overrides DEFAULT_MODEL when given. """ model_name = model or require_env("DEFAULT_MODEL") run_id = str(uuid.uuid4()) with TemporaryDirectory(dir="/tmp") as workspace: root = Path(workspace) deps = WorkspaceDeps(root=root) try: built = _build_model(model_name) result = agent.run_sync( prompt, deps=deps, conversation_id=run_id, model=built, metadata={"model": model_name}, ) # The agent can report done while terraform validate still fails. # Re-validate ourselves and feed any error back as a follow-up turn, # reusing the run id and message history so each retry is an # invoke_agent span under the one invocation trace. Give up after the # budget and raise so the failure is honest rather than a clean run # over a broken workspace. ok, output = _validate(root) attempts = 0 while not ok and attempts < _MAX_VALIDATE_RETRIES: attempts += 1 result = agent.run_sync( _RETRY_PROMPT.format(output=output), deps=deps, conversation_id=run_id, model=built, message_history=result.all_messages(), metadata={"model": model_name}, ) ok, output = _validate(root) if not ok: raise ValidateDidNotConverge(output) except Exception as error: _persist_run(run_id, root, status="error", error=repr(error)) raise _relock_providers(root) _persist_run(run_id, root, status="ok") return RunResult(run_id=run_id, model=model_name, output=str(result.output))"""Read a required environment variable, failing loudly when it is missing."""
from __future__ import annotations
import os
def require_env(name: str) -> str: """Return the value of `name`, or raise if it is unset or empty.
A missing required variable is a deployment fault, not a runtime branch, so we surface it the same way everywhere instead of degrading into a silent no-op. Empty is treated as unset: a blank value is never a real config. """ value = os.environ.get(name) if not value: raise RuntimeError(f"required environment variable {name} is unset") return value"""The Lambda boundary: parse the event, run the agent, shape the response.
This module also owns the INIT wiring. The container CMD targetsagent.lambda_entry.handler, so a unit test that imports agent.core neverconfigures logfire or registers the Firehose audit processor. EverythingLambda-specific lives here, off the core, which is why no runtime-detectioncheck is needed to keep it out of tests."""
from __future__ import annotations
from typing import NotRequired, TypedDict
import logfire
from agent import observabilityfrom agent.core import execute
class HandlerEvent(TypedDict): prompt: str model: NotRequired[str]
class HandlerResponse(TypedDict): status: str run_id: str model: str output: str
def handler(event: HandlerEvent, context: object) -> HandlerResponse: """Lambda entry point: require a prompt, run the agent, wrap the result.
``prompt`` is required; an event without one is a caller error and fails fast rather than running a default. ``model`` overrides DEFAULT_MODEL when given. A run that does not converge raises, so the Lambda reports 5xx and the workspace ships under status error for debugging. """ prompt = event.get("prompt") if not prompt: raise ValueError("event missing required 'prompt'") result = execute(prompt, event.get("model")) return { "status": "ok", "run_id": result.run_id, "model": result.model, "output": result.output, }
def bootstrap() -> None: """Stand up telemetry, then attach the Lambda runtime adapter.
configure() first so the tracer provider exists when the handler is wrapped. instrument_aws_lambda wraps the target named by _HANDLER (agent.lambda_entry.handler) in place, so each invocation becomes one trace. """ observability.configure() logfire.instrument_aws_lambda(handler)
bootstrap()"""Memory probes for the terraform steps.
Lambda's Max Memory Used is misleading for this function. The terraform stepsdownload and unpack the AWS provider (~800 MB) into /tmp, and that file IOfills the kernel page cache, which the cgroup-based billed figure counts butwhich the kernel reclaims under pressure, so it is not OOM risk. ``track_memory``tags a logfire span with three numbers so a run's trace separates real demandfrom cache: the sandbox's used memory (MemTotal - MemAvailable, thenon-reclaimable memory that actually risks OOM), the reclaimable page cache(Cached + Buffers, the bulk of the billed peak), and the peak resident size ofthe largest terraform subprocess. Read together they show real demand staysunder ~1 GB while the billed peak runs to ~2 GB of reclaimable cache."""
from __future__ import annotations
import resourcefrom collections.abc import Iteratorfrom contextlib import contextmanagerfrom pathlib import Path
import logfire
# /proc/meminfo is always present in the Lambda sandbox; the cgroup memory# files are not (neither the v2 /sys/fs/cgroup/memory.current nor the v1# /sys/fs/cgroup/memory/memory.usage_in_bytes is readable there, so reading# them silently returned None). Values are in kibibytes._MEMINFO = Path("/proc/meminfo")
def _memory_snapshot() -> tuple[int, int] | None: """(used, cache) bytes for the whole sandbox, or None when /proc/meminfo is absent.
``used`` is MemTotal - MemAvailable, the non-reclaimable memory in use (the Python runtime plus any live subprocess), which is what actually risks OOM. ``cache`` is Cached + Buffers, the reclaimable page cache that file IO on /tmp fills; Lambda's Max Memory Used counts it but real demand does not, so recording both shows why the billed peak overstates what the function needs. Absent locally (macOS) and in tests, where the caller leaves the attributes unset. """ try: fields = dict(line.split(":", 1) for line in _MEMINFO.read_text().splitlines()) used_kib = int(fields["MemTotal"].split()[0]) - int(fields["MemAvailable"].split()[0]) cache_kib = int(fields["Cached"].split()[0]) + int(fields["Buffers"].split()[0]) except (OSError, KeyError, ValueError, IndexError): return None return used_kib * 1024, cache_kib * 1024
@contextmanagerdef track_memory(step: str) -> Iterator[None]: """Run a block in a logfire span tagged with its memory cost.
On exit, records the sandbox's used memory and reclaimable page cache, and the peak resident size of the largest subprocess waited for so far. ru_maxrss is reported in kilobytes on Linux, so it is scaled to bytes; it is a monotonic high-water mark across all children, not a per-call delta, so compare it between steps to see which one grew the subprocess most. Built with contextmanager, so it doubles as a decorator: ``@track_memory("relock")``. """ # _span_name forces the OTel span name to the interpolated value, so the # trace reads "memory.terraform_validate". Without it logfire keeps the # low-cardinality template "memory.{step}" as the name (its f-string magic # reconstructs the template), leaving the per-step value only in the attribute. with logfire.span("memory.{step}", _span_name=f"memory.{step}", step=step) as span: try: yield finally: if (snapshot := _memory_snapshot()) is not None: used, cache = snapshot span.set_attribute("mem.used_bytes", used) span.set_attribute("mem.cache_bytes", cache) child_peak_kb = resource.getrusage(resource.RUSAGE_CHILDREN).ru_maxrss span.set_attribute("mem.child_max_rss_bytes", child_peak_kb * 1024)"""Build a pydantic-ai model from the SSM-backed registry, per invocation."""
from __future__ import annotations
import jsonimport osfrom functools import cache
from httpx import AsyncClient, HTTPStatusError, Responsefrom pydantic_ai.models import Modelfrom pydantic_ai.models.bedrock import BedrockConverseModelfrom pydantic_ai.models.mistral import MistralModelfrom pydantic_ai.providers.mistral import MistralProviderfrom pydantic_ai.retries import AsyncTenacityTransport, RetryConfig, wait_retry_afterfrom tenacity import retry_if_exception_type, stop_after_attempt, wait_exponential
from agent.env import require_envfrom agent.ssm import fetch_parameter
# Rate limit and transient gateway errors are worth retrying; auth and bad# request fail fast so a real problem is not retried five times._RETRYABLE_STATUS = frozenset({429, 502, 503, 504})
def _raise_for_retryable(response: Response) -> None: if response.status_code in _RETRYABLE_STATUS: response.raise_for_status()
def _retrying_http_client() -> AsyncClient: """An httpx client that retries rate-limit and transient errors.
pydantic-ai does not retry transport errors itself, so a rate-limited Mistral call (the write/init/validate loop can burst past the free-tier per-second cap) would fail the whole run. wait_retry_after honours the Retry-After header Mistral sends on a 429, falling back to exponential backoff. Bedrock uses boto3 with its own retry config, so this is the Mistral client only. """ transport = AsyncTenacityTransport( config=RetryConfig( retry=retry_if_exception_type(HTTPStatusError), wait=wait_retry_after( fallback_strategy=wait_exponential(multiplier=1, max=60), max_wait=300, ), stop=stop_after_attempt(5), reraise=True, ), validate_response=_raise_for_retryable, ) return AsyncClient(transport=transport)
@cachedef _build_model(name: str) -> Model: """Build the pydantic-ai model registered under ``name``.
The registry is an SSM String parameter (MODELS_PARAMETER): each entry names a provider and model id, and Bedrock entries carry the inference-profile ARN. Bedrock authenticates via the Lambda role; Mistral reads an API key from a SecureString. Memoised per name, so the lookup is one GetParameter per container. """ registry = json.loads(fetch_parameter(require_env("MODELS_PARAMETER"))) config = registry[name] provider = config["provider"] if provider == "bedrock": return BedrockConverseModel( config["model_id"], settings={"bedrock_inference_profile": config["inference_profile_arn"]}, ) if provider == "mistral": key_param = os.environ.get("MISTRAL_API_KEY_PARAMETER") if not key_param: raise RuntimeError( f"model {name!r} uses the Mistral API, but MISTRAL_API_KEY_PARAMETER " "is not set. Set MISTRAL_API_KEY and re-apply so the key is wired, or " "select a Bedrock model via DEFAULT_MODEL or the event's model field." ) return MistralModel( config["model_id"], provider=MistralProvider( api_key=fetch_parameter(key_param), http_client=_retrying_http_client(), ), ) raise ValueError(f"unknown provider {provider!r} for model {name!r}")"""Telemetry pipeline: structured logs, the per-trace audit copy, and EMF metrics.
``configure()`` runs at INIT (see handler.py) so the tracer provider and theaudit processor exist before instrument_aws_lambda opens the first invocationspan. The audit copy ships from inside the processor when the trace's root spanends, so the handler needs no flush logic."""
from __future__ import annotations
import jsonimport osimport threadingfrom collections.abc import Callable, Sequence
import boto3import logfireimport structlogfrom google.protobuf import json_formatfrom logfire.sampling import SamplingOptionsfrom opentelemetry.context import ( _SUPPRESS_INSTRUMENTATION_KEY, attach, detach, set_value,)from opentelemetry.exporter.otlp.proto.common._internal.trace_encoder import ( encode_spans,)from opentelemetry.sdk.trace import ReadableSpan, SpanProcessorfrom opentelemetry.trace.status import StatusCode
from agent.env import require_envfrom agent.ssm import fetch_parameter
# JSON logs to stdout, which CloudWatch Logs ingests as-is. The same stream# carries the EMF metric envelope (see _emit_emf), so one structured sink covers# both logs and metrics.structlog.configure( processors=[ structlog.processors.add_log_level, structlog.processors.TimeStamper(fmt="iso"), structlog.processors.EventRenamer("message"), structlog.processors.JSONRenderer(), ], logger_factory=structlog.PrintLoggerFactory(), cache_logger_on_first_use=True,)log = structlog.get_logger()
class PerTraceAuditProcessor(SpanProcessor): """Buffer spans by trace_id, ship as one batch when the local root ends.
The OTel SDK has no `OnTraceComplete` hook, so this implements it against the only signal available: `on_end` fires synchronously, and a span is this process's local root when it has no parent, or a remote parent (context propagated in, e.g. from API Gateway), which `SpanContext.is_remote` marks. Late children (ended on a transport thread after the root shipped) are dropped, mirroring logfire's tail sampler. See pydantic/logfire#1034. """
def __init__( self, on_trace_complete: Callable[[Sequence[ReadableSpan]], None], ) -> None: self._on_trace_complete = on_trace_complete self._buffers: dict[int, list[ReadableSpan]] = {} self._shipped: set[int] = set() self._lock = threading.Lock()
def on_end(self, span: ReadableSpan) -> None: if not (span.context and span.context.trace_flags.sampled): return trace_id = span.context.trace_id with self._lock: if trace_id in self._shipped: return self._buffers.setdefault(trace_id, []).append(span) if span.parent is not None and not span.parent.is_remote: return spans = self._buffers.pop(trace_id) self._shipped.add(trace_id) self._ship(spans)
def force_flush(self, timeout_millis: int = 30000) -> bool: with self._lock: pending = list(self._buffers.values()) self._shipped.update(self._buffers) self._buffers.clear() for spans in pending: self._ship(spans) return True
def shutdown(self) -> None: self.force_flush()
def _ship(self, spans: Sequence[ReadableSpan]) -> None: # Suppress instrumentation around the callback so an instrumented # boto3 client inside it does not emit a span that re-enters on_end. token = attach(set_value(_SUPPRESS_INSTRUMENTATION_KEY, True)) try: self._on_trace_complete(spans) finally: detach(token)
_firehose = boto3.client("firehose")_DELIVERY_STREAM = require_env("FIREHOSE_DELIVERY_STREAM")
def _ship_trace(spans: Sequence[ReadableSpan]) -> None: """Serialise one trace as OTLP-JSON and ship it as a single Firehose record.""" payload = json_format.MessageToJson(encode_spans(spans), indent=None) + "\n" _firehose.put_record( DeliveryStreamName=_DELIVERY_STREAM, Record={"Data": payload.encode("utf-8")}, )
def _emf_record(span: ReadableSpan) -> dict: """Build the EMF envelope for one agent-run span.
pydantic-ai records gen_ai.usage.* on the agent-run span as the run total, so a single read is the correct total. The model dimension is the registry key the handler passed as run metadata, read back so a Bedrock run and a Mistral run land on one set of widgets. """ attributes = span.attributes or {} model = json.loads(attributes["metadata"]).get("model", "unknown") errored = span.status.status_code is StatusCode.ERROR return { "_aws": { "Timestamp": span.end_time // 1_000_000, "CloudWatchMetrics": [ { "Namespace": require_env("METRICS_NAMESPACE"), "Dimensions": [["Model"]], "Metrics": [ {"Name": "InputTokens", "Unit": "Count"}, {"Name": "OutputTokens", "Unit": "Count"}, {"Name": "CacheReadTokens", "Unit": "Count"}, {"Name": "CacheWriteTokens", "Unit": "Count"}, {"Name": "Latency", "Unit": "Milliseconds"}, {"Name": "Invocations", "Unit": "Count"}, {"Name": "Errors", "Unit": "Count"}, ], } ], }, "Model": model, "InputTokens": attributes.get("gen_ai.usage.input_tokens", 0), "OutputTokens": attributes.get("gen_ai.usage.output_tokens", 0), # pydantic-ai sets these only when non-zero; providers without prompt # caching (the Mistral API) never report them, so default to 0. "CacheReadTokens": attributes.get("gen_ai.usage.cache_read.input_tokens", 0), "CacheWriteTokens": attributes.get("gen_ai.usage.cache_creation.input_tokens", 0), "Latency": (span.end_time - span.start_time) / 1_000_000, "Invocations": 1, "Errors": 1 if errored else 0, }
def _emit_emf(spans: Sequence[ReadableSpan]) -> None: """Emit one EMF metric line per agent run in the trace.
Off Bedrock there are no AWS/Bedrock metrics, so the dashboard reads these. The trace root is the Lambda invocation span, so metrics come off the agent-run spans nested under it, found by the `metadata` attribute pydantic-ai stamps on every run (a caller-side retry holds several, so one line each). CloudWatch Logs extracts the metrics from the structured line. """ for span in spans: if span.attributes and "metadata" in span.attributes: log.info("trace_metrics", **_emf_record(span))
def _on_trace_complete(spans: Sequence[ReadableSpan]) -> None: """Ship the audit copy, then emit metrics: one hook, two sinks.""" _ship_trace(spans) _emit_emf(spans)
def _logfire_token() -> str | None: """Logfire token from SSM, or None when the integration is not wired.""" name = os.environ.get("LOGFIRE_TOKEN_PARAMETER") return fetch_parameter(name) if name else None
def configure() -> None: """Wire logfire at INIT: register the audit processor and instrument pydantic-ai.
head=1.0 / tail=None because this is an audit pipeline: every trace must reach S3, and volume is low (one trace per invocation). Splitting the rates (say 1% to Logfire, 100% to S3) is possible with an extra sampler. include_content=True keeps the audit copy useful for forensics; flip it to False if prompts ever carry PII or secrets. version=5 pins the GenAI span schema so the audit copy stays stable across pydantic-ai releases. """ if token := _logfire_token(): os.environ["LOGFIRE_TOKEN"] = token logfire.configure( send_to_logfire="if-token-present", sampling=SamplingOptions(head=1.0, tail=None), additional_span_processors=[PerTraceAuditProcessor(_on_trace_complete)], ) logfire.instrument_pydantic_ai(version=5, include_content=True)"""Park a run's workspace in S3, and re-lock providers before it ships."""
from __future__ import annotations
import jsonimport subprocessfrom collections.abc import Iteratorfrom pathlib import Path
import boto3
from agent.env import require_envfrom agent.memory import track_memoryfrom agent.observability import log
def _persist_run(run_id: str, workspace: Path, status: str, error: str | None = None) -> None: """Park the workspace and a minimal result marker under runs/<run_id>/.
result.json carries only what the audit trace does not: prompt, output, and messages already live in the trace under the same conversation id, so copying them here would create a second source of truth. """ bucket = require_env("RUNS_BUCKET") s3 = boto3.client("s3") for file in _workspace_files(workspace): key = f"runs/{run_id}/workspace/{file.relative_to(workspace)}" s3.put_object(Bucket=bucket, Key=key, Body=file.read_bytes()) result = {"status": status} | ({"error": error} if error else {}) s3.put_object( Bucket=bucket, Key=f"runs/{run_id}/result.json", Body=json.dumps(result).encode(), )
def _workspace_files(workspace: Path) -> Iterator[Path]: """Every file except .terraform/, which is init scratch plus the provider downloaded into /tmp, gigabytes of noise per run. The top-level .terraform.lock.hcl is the reproducibility record and stays. """ for path in sorted(workspace.rglob("*")): if ".terraform" in path.relative_to(workspace).parts: continue if path.is_file(): yield path
# init inside the arm64 Lambda locks only linux_arm64, so a reviewer or CI on# another platform hits a checksum error. Re-lock the platforms they are likely# to run before the workspace ships. One call per platform rather than one with# three -platform flags: `providers lock` is additive, so each call merges its# platform and leaves the others, and a fresh process per platform keeps the# peak to one platform's footprint. Best-effort and independent: a failure on# one is logged and the rest still run._LOCK_PLATFORMS = ("linux_amd64", "linux_arm64", "darwin_arm64")
def _relock_providers(workspace: Path) -> None: if not (workspace / ".terraform.lock.hcl").exists(): return for platform in _LOCK_PLATFORMS: with track_memory(f"relock.{platform}"): result = subprocess.run( ["terraform", "providers", "lock", "-no-color", f"-platform={platform}"], cwd=workspace, capture_output=True, text=True, ) if result.returncode != 0: log.warning( "provider re-lock failed", platform=platform, stdout=result.stdout, stderr=result.stderr, )"""SSM Parameter Store access, shared by the model registry and the Logfire token fetch."""
from __future__ import annotations
import boto3
def fetch_parameter(name: str) -> str: """Read one parameter from SSM Parameter Store.
WithDecryption is a no-op on a plain String, so this covers String and SecureString alike. A direct GetParameter call, because container-image Lambdas cannot attach the Parameters and Secrets extension layer the zip package used. The client is built per call so moto can intercept it in tests. """ response = boto3.client("ssm").get_parameter(Name=name, WithDecryption=True) return response["Parameter"]["Value"]"""Tool surface for the terraform-pr-agent.
Each function below is registered on the Agent in handler.py and exposedto the model as a callable tool. The bodies are intentionally empty inthis scaffold: the post fills them in section by section, so the readercan see the agent's behaviour change as each tool comes online.
All tools take ``RunContext[WorkspaceDeps]`` so the workspace root isthreaded through ``ctx.deps.root`` instead of read from a module global.That keeps tests, evals, and multi-tenant runs from sharing state."""
from __future__ import annotations
import subprocessfrom pathlib import Path
from pydantic import BaseModel, ConfigDict, Fieldfrom pydantic_ai import ModelRetry, RunContext
from agent.memory import track_memory
class WorkspaceDeps(BaseModel): """Per-run dependencies threaded through ``RunContext``.
``root`` is the directory the agent is allowed to read, write, and validate inside. Tools resolve every path relative to it and reject anything that escapes the root, so the agent cannot reach outside the workspace via ``..`` or absolute paths. """
model_config = ConfigDict(arbitrary_types_allowed=True)
root: Path files_read: set[Path] = Field(default_factory=set)
def list_files(ctx: RunContext[WorkspaceDeps], path: str = ".") -> list[str]: """List files under ``path`` relative to the workspace root.""" return [ str(p.relative_to(ctx.deps.root)) for p in _resolve_absolute_folder(ctx, path).iterdir() ]
def read_file(ctx: RunContext[WorkspaceDeps], path: str) -> str: """Read the file at ``path`` and return its contents.""" file = _resolve_absolute_file(ctx, path) if not file.exists(): raise ModelRetry(f"File {path} does not exist.") with file.open() as f: ctx.deps.files_read.add(file) return f.read()
def write_file(ctx: RunContext[WorkspaceDeps], path: str, contents: str) -> None: """Create or overwrite the file at ``path`` with ``contents``.""" file = _resolve_absolute_path(ctx, path) if file.exists() and file not in ctx.deps.files_read: raise ModelRetry( f"File {path} already exists. If you want to overwrite it, then delete it first." ) with file.open("w") as f: # agent wrote it and knows the content ctx.deps.files_read.add(file) f.write(contents)
def edit_file( ctx: RunContext[WorkspaceDeps], path: str, old_string: str, new_string: str,) -> None: """Replace ``old_string`` with ``new_string`` in the file at ``path``.""" file = _resolve_absolute_file(ctx, path) if not file.exists(): raise ModelRetry(f"File {path} does not exist.") if file not in ctx.deps.files_read: raise ModelRetry(f"File {path} was not read. If you want to edit it, then read it first.") with file.open("r+") as f: contents = f.read() if old_string not in contents: raise ModelRetry(f"String {old_string} not found in file {path}.") if contents.count(old_string) > 1: raise ModelRetry(f"String {old_string} found more than once in file {path}.") f.seek(0) f.write(contents.replace(old_string, new_string)) f.truncate()
def delete_file(ctx: RunContext[WorkspaceDeps], path: str) -> None: """Delete the file at ``path``.""" file = _resolve_absolute_file(ctx, path) if file not in ctx.deps.files_read: raise ModelRetry(f"File {path} was not read. If you want to delete it, then read it first.") file.unlink()
def terraform_init(ctx: RunContext[WorkspaceDeps]) -> str: """Run ``terraform init`` in the workspace.
Required once before the first ``terraform_validate`` and again after provider or module requirements change. """ with track_memory("terraform_init"): init = subprocess.run( ["terraform", "init", "-backend=false", "-input=false", "-no-color"], cwd=ctx.deps.root, capture_output=True, text=True, ) if init.returncode != 0: raise ModelRetry(f"terraform init failed:\n{init.stdout}{init.stderr}") return "OK: terraform init completed."
def _validate(root: Path) -> tuple[bool, str]: """Run ``terraform validate`` in ``root``; return (passed, combined output).
The agent reaches this through the tool below; the caller-side retry in handler.py calls it directly to re-check the workspace after the run. """ with track_memory("terraform_validate"): result = subprocess.run( ["terraform", "validate", "-no-color"], cwd=root, capture_output=True, text=True, ) return result.returncode == 0, f"{result.stdout}{result.stderr}"
def terraform_validate(ctx: RunContext[WorkspaceDeps]) -> str: """Run ``terraform validate`` in the workspace and return its output.""" ok, output = _validate(ctx.deps.root) if ok: return "OK: terraform validate passed." raise ModelRetry(f"terraform validate failed:\n{output}")
def _resolve_absolute_folder(ctx: RunContext[WorkspaceDeps], path: str): if not (absolute_path := _resolve_absolute_path(ctx, path)).is_dir(): raise ModelRetry(f"Path {path} must be a directory.") return absolute_path
def _resolve_absolute_file(ctx: RunContext[WorkspaceDeps], path: str): if not (absolute_path := _resolve_absolute_path(ctx, path)).is_file(): raise ModelRetry(f"Path {path} must be a file.") return absolute_path
def _resolve_absolute_path(ctx: RunContext[WorkspaceDeps], path: str): root = ctx.deps.root.resolve() absolute_path = (root / Path(path)).resolve() if not absolute_path.is_relative_to(root): raise ModelRetry( f"Path {path} must be relative to the workspace root, " f"it cannot be absolute or walk up the directory tree." ) return absolute_pathFROM public.ecr.aws/lambda/python:3.13
COPY handler.py ${LAMBDA_TASK_ROOT}/CMD ["handler.handler"]def handler(event, context): return { "status": "placeholder", "note": "run scripts/build-lambda.sh to build and deploy the real image", }locals { cloudwatch_region = data.aws_region.current.region dashboard_name = "terraform-pr-agent" lambda_name = aws_lambda_function.agent.function_name
# The model widgets read the EMF metrics the handler emits (namespace # local.metrics_namespace, dimensioned by Model), not AWS/Bedrock, so a # Bedrock model and a Mistral-API model land in the same widgets. One line # per registry model, built by iterating keys(local.models). model_keys = keys(local.models)}
resource "aws_cloudwatch_dashboard" "agent" { dashboard_name = local.dashboard_name dashboard_body = jsonencode({ widgets = [ { type = "text" x = 0 y = 0 width = 24 height = 2 properties = { markdown = "## Lambda\nContainer-image function health: invocations and errors, end to end duration, cold start init duration (Lambda Insights emits `init_duration` only on a cold start), and the memory and `/tmp` footprint behind the `memory_size` and `ephemeral_storage` sizing." } }, { type = "metric" x = 0 y = 2 width = 12 height = 6 properties = { title = "Lambda invocations and errors" region = local.cloudwatch_region view = "timeSeries" stat = "Sum" period = 60 metrics = [ ["AWS/Lambda", "Invocations", "FunctionName", local.lambda_name, { label = "${local.lambda_name} / invocations" }], [".", "Errors", ".", ".", { label = "${local.lambda_name} / errors" }], [".", "Throttles", ".", ".", { label = "${local.lambda_name} / throttles" }], ] } }, { type = "metric" x = 12 y = 2 width = 12 height = 6 properties = { title = "Lambda duration (ms)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ ["AWS/Lambda", "Duration", "FunctionName", local.lambda_name, { label = "${local.lambda_name} / avg", stat = "Average" }], [".", ".", ".", ".", { label = "${local.lambda_name} / p99", stat = "p99" }], ] } }, { type = "metric" x = 0 y = 8 width = 12 height = 6 properties = { title = "Cold start init duration (ms)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ # Insights reports init_duration only when an init phase happened, # so points appear only on cold starts. ["LambdaInsights", "init_duration", "function_name", local.lambda_name, { label = "${local.lambda_name} / init avg (ms)", stat = "Average" }], [".", ".", ".", ".", { label = "${local.lambda_name} / init max (ms)", stat = "Maximum" }], ] } }, { type = "metric" x = 12 y = 8 width = 12 height = 6 properties = { title = "Memory used (MB)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ # used_memory_max is the cgroup figure (Max Memory Used), which # counts the reclaimable /tmp page cache and so reads ~2 GB while # real demand is under 1 GB. Backs the memory_size comment in # lambda.tf. ["LambdaInsights", "used_memory_max", "function_name", local.lambda_name, { label = "${local.lambda_name} / memory max (MB)", stat = "Maximum" }], ] } }, { type = "metric" x = 0 y = 14 width = 12 height = 6 properties = { title = "/tmp used (bytes)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ # tmp_used tracks the ~800 MB provider download into /tmp, behind # the 4 GB ephemeral_storage sizing in lambda.tf. ["LambdaInsights", "tmp_used", "function_name", local.lambda_name, { label = "${local.lambda_name} / tmp used (B)", stat = "Maximum" }], ] } }, { type = "text" x = 0 y = 20 width = 24 height = 2 properties = { markdown = "## Model\nPer-model usage from the handler's EMF metrics (namespace `local.metrics_namespace`, dimensioned by `Model`), so Bedrock and Mistral-API models share one set of widgets: tokens, invocations and errors, latency, and cache reads and writes." } }, { type = "metric" x = 0 y = 22 width = 12 height = 6 properties = { title = "Tokens" region = local.cloudwatch_region view = "timeSeries" stat = "Sum" period = 60 metrics = [ for m in flatten([ for key in local.model_keys : [ { metric = "InputTokens", label = "${key} / input", key = key }, { metric = "OutputTokens", label = "${key} / output", key = key }, ] ]) : [local.metrics_namespace, m.metric, "Model", m.key, { label = m.label }] ] } }, { type = "metric" x = 12 y = 22 width = 12 height = 6 properties = { title = "Invocations and errors" region = local.cloudwatch_region view = "timeSeries" stat = "Sum" period = 60 metrics = [ for m in flatten([ for key in local.model_keys : [ { metric = "Invocations", label = "${key} / invocations", key = key }, { metric = "Errors", label = "${key} / errors", key = key }, ] ]) : [local.metrics_namespace, m.metric, "Model", m.key, { label = m.label }] ] } }, { type = "metric" x = 0 y = 28 width = 12 height = 6 properties = { title = "Latency (ms)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ for m in flatten([ for key in local.model_keys : [ { label = "${key} / avg", key = key, stat = "Average" }, { label = "${key} / p99", key = key, stat = "p99" }, ] ]) : [local.metrics_namespace, "Latency", "Model", m.key, { label = m.label, stat = m.stat }] ] } }, { type = "metric" x = 12 y = 28 width = 12 height = 6 properties = { title = "Cache tokens" region = local.cloudwatch_region view = "timeSeries" stat = "Sum" period = 60 metrics = [ for m in flatten([ for key in local.model_keys : [ { metric = "CacheReadTokens", label = "${key} / cache read", key = key }, { metric = "CacheWriteTokens", label = "${key} / cache write", key = key }, ] ]) : [local.metrics_namespace, m.metric, "Model", m.key, { label = m.label }] ] } }, ] })}
output "cloudwatch_dashboard_url" { value = format( "https://%s.console.aws.amazon.com/cloudwatch/home?region=%s#dashboards/dashboard/%s", local.cloudwatch_region, local.cloudwatch_region, aws_cloudwatch_dashboard.agent.dashboard_name, )}resource "aws_ecr_repository" "agent" { name = "terraform-pr-agent"
# Deploys re-push the :latest and :placeholder tags in place, the same # out-of-band code-ship pattern as the zip flow this replaces. Immutable # tags would force a fresh tag per build. #trivy:ignore:avd-aws-0031 image_tag_mutability = "MUTABLE"
# Tutorial teardown: terraform destroy must succeed while images exist. force_delete = true
image_scanning_configuration { scan_on_push = true }
# The AWS-managed AES256 key is enough here: the image holds no secret # material, and a CMK adds cost and key-policy surface for nothing. #trivy:ignore:avd-aws-0033 encryption_configuration { encryption_type = "AES256" }}
# Container twin of the zip flow's archive_file placeholder: the function# resource needs a pullable image at create time, so terraform seeds a# minimal one. Create-only (input never changes), so scripts/build-lambda.sh# owns every push after this.resource "terraform_data" "placeholder_image" { input = aws_ecr_repository.agent.repository_url
# Needs docker and the aws cli on the machine running apply; both are # already prerequisites for the series. provisioner "local-exec" { command = <<-EOT aws ecr get-login-password --region ${data.aws_region.current.region} | docker login --username AWS --password-stdin ${split("/", aws_ecr_repository.agent.repository_url)[0]} docker buildx build --platform linux/arm64 --provenance=false \ -t ${aws_ecr_repository.agent.repository_url}:placeholder \ --push ${path.module}/placeholder EOT }}data "aws_iam_policy_document" "lambda_assume" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["lambda.amazonaws.com"] } }}
# trivy:ignore:avd-aws-0057# Bedrock foundation-model ARNs do not pin to the caller region (the inference# profile fans out cross-region), and Marketplace subscription actions are# global by design.data "aws_iam_policy_document" "lambda_permissions" { # Bedrock invocation. Same shape as iam.tf's bedrock_invoke; copied # here so the Lambda role is self-contained and does not require # the user-role policy to also be attached to the Lambda role. statement { actions = [ "bedrock:Converse", "bedrock:ConverseStream", "bedrock:InvokeModel", "bedrock:InvokeModelWithResponseStream", ] # Bedrock foundation-model ARNs do not pin to the caller region; the # inference profile fans out cross-region, so the * region segment is required. #trivy:ignore:avd-aws-0057 resources = [ aws_bedrock_inference_profile.agent.arn, local.system_inference_profile_arn, "arn:aws:bedrock:*::foundation-model/${local.bedrock_model_id}", ] }
statement { actions = [ "aws-marketplace:Subscribe", "aws-marketplace:Unsubscribe", "aws-marketplace:ViewSubscriptions", ] # Marketplace subscription actions are global by design. #trivy:ignore:avd-aws-0057 resources = ["*"] }
# Model registry read. A plain String parameter, so no KMS is involved. statement { actions = ["ssm:GetParameter"] resources = [aws_ssm_parameter.models.arn] }
# SSM SecureString read for the Logfire token, only when wired. dynamic "statement" { for_each = local.logfire_token_wired ? [1] : [] content { actions = ["ssm:GetParameter"] resources = [aws_ssm_parameter.logfire_token[0].arn] } }
# SSM SecureString read for the Mistral API key, only when wired. dynamic "statement" { for_each = local.mistral_key_wired ? [1] : [] content { actions = ["ssm:GetParameter"] resources = [aws_ssm_parameter.mistral_api_key[0].arn] } }
# KMS Decrypt on the AWS-managed SSM key, required to decrypt any # SecureString read via GetParameter. Present when either secret is wired. dynamic "statement" { for_each = local.logfire_token_wired || local.mistral_key_wired ? [1] : [] content { actions = ["kms:Decrypt"] resources = [ "arn:aws:kms:${data.aws_region.current.region}:${data.aws_caller_identity.current.account_id}:alias/aws/ssm", ] } }
statement { actions = [ "firehose:PutRecord", "firehose:PutRecordBatch", ] resources = [aws_kinesis_firehose_delivery_stream.audit.arn] }
# Write-only: the handler parks run artifacts and never reads them back, # so there is no GetObject or ListBucket. Scoped to the runs/ prefix the # handler writes under. statement { actions = ["s3:PutObject"] resources = ["${aws_s3_bucket.runs.arn}/runs/*"] }}
resource "aws_iam_role" "lambda" { name = "terraform-pr-agent-lambda" assume_role_policy = data.aws_iam_policy_document.lambda_assume.json}
resource "aws_iam_role_policy_attachment" "lambda_basic_execution" { role = aws_iam_role.lambda.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole"}
resource "aws_iam_role_policy" "lambda_permissions" { name = "terraform-pr-agent-lambda-permissions" role = aws_iam_role.lambda.id policy = data.aws_iam_policy_document.lambda_permissions.json}
# The Lambda Insights extension baked into the image ships its metrics# through its own /aws/lambda-insights log group; the AWS-managed policy# grants exactly that write path.resource "aws_iam_role_policy_attachment" "lambda_insights" { role = aws_iam_role.lambda.name policy_arn = "arn:aws:iam::aws:policy/CloudWatchLambdaInsightsExecutionRolePolicy"}
resource "aws_lambda_function" "agent" { function_name = "terraform-pr-agent" role = aws_iam_role.lambda.arn architectures = ["arm64"]
# The handler entry point comes from the image's CMD; the runtime, # handler, and layers attributes only apply to zip packages. package_type = "Image" image_uri = "${aws_ecr_repository.agent.repository_url}:placeholder"
# Max Memory Used overstates what this function needs. It runs to ~2 GB on a # heavy run, but the track_memory spans (see agent/memory.py) show the real, # non-reclaimable demand stays under ~1 GB: ~315 MB resident for the Python # runtime plus a transient ~420 MB while terraform validate loads the # provider schema. The rest is reclaimable page cache from the ~800 MB # provider download and re-lock unpacks doing file IO on /tmp, which the # cgroup-based billed figure counts but the kernel drops under pressure, so # it is not OOM risk. Memory is therefore not the binding constraint here. # 3008 is set for the vCPU it buys, not the RAM: above 1769 MB Lambda gives a # full core (3008 is ~1.7), which speeds the run. Drop it toward ~1769 if # latency matters less than cost; do not raise it for memory headroom. memory_size = 3008
# The per-run tool budget is the runaway guard; the timeout only has to # accommodate several model turns with init + validate rounds in between. timeout = 300
# Two things land in /tmp: terraform init downloads the AWS provider # (~800 MB) into the workspace, and the post-run re-lock unpacks the # provider for three platforms (another ~2 GB) to write a portable lock # file. 4 GB covers both with headroom; the default 512 MB would not. ephemeral_storage { size = 4096 }
tracing_config { mode = "Active" }
environment { variables = merge( { MODELS_PARAMETER = aws_ssm_parameter.models.name DEFAULT_MODEL = var.default_model METRICS_NAMESPACE = local.metrics_namespace FIREHOSE_DELIVERY_STREAM = aws_kinesis_firehose_delivery_stream.audit.name RUNS_BUCKET = aws_s3_bucket.runs.bucket }, local.logfire_token_wired ? { LOGFIRE_TOKEN_PARAMETER = local.logfire_token_parameter_name } : {}, local.mistral_key_wired ? { MISTRAL_API_KEY_PARAMETER = aws_ssm_parameter.mistral_api_key[0].name } : {}, ) }
# Code ships out of band: scripts/build-lambda.sh pushes a new image and # calls update-function-code, so terraform must not flip the function # back to the placeholder on the next apply. lifecycle { ignore_changes = [image_uri] }
depends_on = [ aws_iam_role_policy_attachment.lambda_basic_execution, aws_iam_role_policy_attachment.lambda_insights, aws_iam_role_policy.lambda_permissions, terraform_data.placeholder_image, ]}
output "lambda_function_name" { value = aws_lambda_function.agent.function_name}
output "lambda_function_arn" { value = aws_lambda_function.agent.arn}locals { runs_bucket_name = "terraform-pr-agent-runs-${data.aws_caller_identity.current.account_id}-${data.aws_region.current.region}"}
# Stopgap output sink until the GitHub PR flow lands in a later post: the# agent's /tmp workspace dies with the invocation, so each run parks its# files and a minimal result marker under runs/<run_id>/ here. Nothing in# this bucket is a system of record (the Object Lock audit bucket is), so# it takes the opposite posture of audit-bucket.tf: force_destroy so# terraform destroy empties and removes the bucket, no versioning, and# SSE-S3 instead of a KMS key that would outlive the bucket's purpose.# Access logging would require a second bucket, which transient run# outputs are not worth.#trivy:ignore:avd-aws-0089#trivy:ignore:avd-aws-0090resource "aws_s3_bucket" "runs" { bucket = local.runs_bucket_name force_destroy = true}
resource "aws_s3_bucket_public_access_block" "runs" { bucket = aws_s3_bucket.runs.id block_public_acls = true block_public_policy = true ignore_public_acls = true restrict_public_buckets = true}
# Agent-written HCL, not secrets; SSE-S3 keeps the temporary bucket free# of a CMK lifecycle.#trivy:ignore:avd-aws-0132resource "aws_s3_bucket_server_side_encryption_configuration" "runs" { bucket = aws_s3_bucket.runs.id
rule { apply_server_side_encryption_by_default { sse_algorithm = "AES256" } }}variable "alert_email" { description = "Email address subscribed to the agent alerts SNS topic. Set via TF_VAR_alert_email." type = string}
variable "daily_token_alarm_threshold" { description = "Daily combined input + output token threshold. Crossing it sends an email via SNS." type = number default = 1000000}
variable "audit_retention_days" { type = number description = "Object Lock default retention in days. Tutorial default is 7 so the bucket is easy to clean up; production audit horizons are typically years (e.g. 2555 for SOX-style controls)." default = 7}
variable "logfire_token" { type = string description = "Logfire write token. Leave empty to skip the Logfire integration. Set via TF_VAR_logfire_token in .envrc.local." default = "" sensitive = true}
variable "mistral_api_key" { type = string description = "Mistral API key. Leave empty to skip the Mistral providers (Bedrock models still work). Set via TF_VAR_mistral_api_key in .envrc.local." default = "" sensitive = true}
variable "default_model" { type = string description = "Registry key of the model the agent runs with (see models.tf). One of: haiku, mistral-large, devstral-small." default = "mistral-large"}#!/usr/bin/env bash# Build and push the terraform-pr-agent container image, then point the# Lambda at it. Terraform owns the ECR repo and the function (infra/);# this script only ships code, the same split as the zip flow it# replaces.## Runs from anywhere; cd's to the project root (the dir holding the# Dockerfile).set -euo pipefail
cd "$(dirname "$0")/.."
# Make sure the lock matches pyproject.toml before the Dockerfile copies# it into the build.uv sync --quiet
# Terraform created the repo; asking AWS for the URI keeps the account# id and region out of this script.repo_uri="$(aws ecr describe-repositories \ --repository-names terraform-pr-agent \ --query 'repositories[0].repositoryUri' --output text)"registry="${repo_uri%%/*}"
aws ecr get-login-password | docker login --username AWS --password-stdin "$registry"
# --provenance=false: buildx otherwise wraps the image in an OCI image# index for the provenance attestation, which Lambda rejects.docker buildx build --platform linux/arm64 --provenance=false \ -t "$repo_uri:latest" --push .
# update-function-code resolves :latest to a digest at call time, so a# re-pushed tag rolls the function forward. No --publish needed:# invocations hit $LATEST.aws lambda update-function-code \ --function-name terraform-pr-agent \ --image-uri "$repo_uri:latest" >/dev/nullaws lambda wait function-updated --function-name terraform-pr-agent
echo "deployed: $repo_uri:latest"-- OR REPLACE so re-running this script is idempotent: a plain-- CREATE PERSISTENT SECRET errors on the second run (the secret persists-- in ~/.duckdb), which aborts the script before the view below is rebuilt-- and leaves a stale `traces` view in place.CREATE OR REPLACE PERSISTENT SECRET ( TYPE s3, PROVIDER credential_chain, REFRESH auto);SET VARIABLE audit_bucket = getenv('AUDIT_BUCKET');
-- hive_partitioning = true reads year=YYYY/month=MM/day=DD/ from the-- object path as virtual columns, so the partition predicate in a-- query below prunes objects before any file is opened.CREATE OR REPLACE VIEW traces ASWITH spans AS ( -- Flatten the OTLP-JSON envelope into one row per span, with the -- common span fields lifted out as named columns so downstream -- CTEs and ad-hoc queries can work against `name`, `trace_id`, -- `dur_ms`, etc. without re-doing the struct navigation each time. SELECT year, month, day, span.name AS name, lower(hex(from_base64(span.traceId::VARCHAR))) AS trace_id, lower(hex(from_base64(span.spanId::VARCHAR))) AS span_id, lower(hex(from_base64(span.parentSpanId::VARCHAR))) AS parent_span_id, make_timestamp_ns(span.startTimeUnixNano::BIGINT) AS started, make_timestamp_ns(span.endTimeUnixNano::BIGINT) AS ended, (span.endTimeUnixNano::BIGINT - span.startTimeUnixNano::BIGINT) / 1e6 AS dur_ms, span.status.code::VARCHAR AS status_code, span.attributes AS attributes, data.filename AS source_file, -- Firehose names objects <stream>-<ver>-<YYYY-MM-DD-HH-MM-SS>-<uuid>.gz; -- stripping the trailing -<uuid>.gz collapses rows from the same flush -- batch onto a stable key for grouping. regexp_replace( split_part(data.filename, '/', -1), '-[0-9a-f]{8}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{4}-[0-9a-f]{12}\.gz$', '' ) AS batch_key FROM read_ndjson( 's3://' || getvariable('audit_bucket') || '/traces/**/*.gz', compression = 'gzip', hive_partitioning = true, filename = true) AS data , UNNEST(data.resourceSpans) AS u1(rs) , UNNEST(rs.scopeSpans) AS u2(ss) , UNNEST(ss.spans) AS u3(span)),roots AS ( -- One row per agent run: pydantic-ai's invoke_agent span, identified by -- the GenAI operation rather than by being the parentless span. -- instrument_aws_lambda now roots each trace at the SpanKind.SERVER -- invocation span, so the agent run is a child of it, not the trace root. -- (A caller-side retry would put several invoke_agent spans under one -- invocation; the trace_id join below would then cross them, so that -- case wants each chat tied to its enclosing run instead.) SELECT * FROM spans WHERE list_filter(attributes, x -> x.key = 'gen_ai.operation.name')[1] .value.stringValue = 'invoke_agent'),chats AS ( -- Per-trace summary of the LLM call: pulls the GenAI semantic -- convention attributes off the chat span and exposes each as a -- named column. SELECT trace_id, list_filter(attributes, x -> x.key = 'gen_ai.system')[1].value.stringValue AS gen_ai_system, list_filter(attributes, x -> x.key = 'gen_ai.operation.name')[1].value.stringValue AS operation, list_filter(attributes, x -> x.key = 'gen_ai.request.model')[1].value.stringValue AS request_model, list_filter(attributes, x -> x.key = 'gen_ai.response.model')[1].value.stringValue AS response_model, list_filter(attributes, x -> x.key = 'gen_ai.usage.input_tokens')[1].value.intValue::BIGINT AS in_tokens, list_filter(attributes, x -> x.key = 'gen_ai.usage.output_tokens')[1].value.intValue::BIGINT AS out_tokens, list_filter(attributes, x -> x.key = 'gen_ai.response.finish_reasons')[1] .value.arrayValue.values[1].stringValue AS finish, list_filter(attributes, x -> x.key = 'gen_ai.conversation.id')[1].value.stringValue AS conversation_id, list_filter(attributes, x -> x.key = 'gen_ai.agent.name')[1].value.stringValue AS agent_name, list_filter(attributes, x -> x.key = 'gen_ai.agent.call.id')[1].value.stringValue AS agent_call_id, list_filter(attributes, x -> x.key = 'gen_ai.input.messages')[1].value.stringValue AS input_messages, list_filter(attributes, x -> x.key = 'gen_ai.output.messages')[1].value.stringValue AS output_messages FROM spans WHERE name LIKE 'chat %'),final_chats AS ( -- The run's closing assistant message, one row per trace: the chat span -- that ended last. Its first text part is the summary the agent returns, -- so unlike the per-row assistant_response convenience column it is not -- knocked out by the tool-call turns a multi-turn run is mostly made of. SELECT trace_id, output_messages FROM ( SELECT trace_id, list_filter(attributes, x -> x.key = 'gen_ai.output.messages')[1].value.stringValue AS output_messages, row_number() OVER (PARTITION BY trace_id ORDER BY ended DESC) AS rn FROM spans WHERE name LIKE 'chat %' ) WHERE rn = 1)SELECT roots.started, roots.year, roots.month, roots.day, roots.trace_id, substr(roots.trace_id, 1, 8) AS trace, roots.batch_key, roots.source_file, roots.dur_ms, regexp_extract(chats.request_model, '[^./]+$') AS model, chats.in_tokens, chats.out_tokens, chats.finish, chats.agent_name, chats.conversation_id, -- Convenience columns for the common single-turn shape: system at -- input[0], user at input[1], assistant at output[0]. Multi-turn -- runs invalidate the indices, so reach for input_messages and -- output_messages directly for those. json_extract_string(chats.input_messages, '$[0].parts[0].content') AS system_prompt, json_extract_string(chats.input_messages, '$[1].parts[0].content') AS user_prompt, json_extract_string(chats.output_messages, '$[0].parts[0].content') AS assistant_response, -- One reliable assistant summary per trace (the closing turn), repeated -- across the trace's fanned-out rows; see the final_chats CTE. json_extract_string(final_chats.output_messages, '$[0].parts[0].content') AS final_response, chats.input_messages, chats.output_messages, -- Per the OTel spec, instrumentation libraries leave status unset -- on success (only application code may set it to Ok). Every OTel -- backend treats unset as "no error reported"; we render the same. CASE roots.status_code WHEN 'STATUS_CODE_ERROR' THEN 'err' ELSE 'ok' END AS statusFROM rootsJOIN chats USING (trace_id)LEFT JOIN final_chats USING (trace_id);"""Shared test setup.
handler.py reads FIREHOSE_DELIVERY_STREAM at import time, so a stand-in is setbefore any test imports it. The model registry and default model are read atINVOKE time; tests stub _build_model and swap in a scripted FunctionModel viaagent.override, so no real AWS or Mistral call is ever made. The S3 upload runsagainst moto."""
import os
import logfire
# The tools and the re-lock open logfire spans via track_memory. Outside# Lambda nothing configures logfire, so pin it to local-only here to keep# spans as no-ops and off the network during the test run.logfire.configure(send_to_logfire=False)
os.environ.setdefault("AWS_DEFAULT_REGION", "eu-central-1")os.environ.setdefault("FIREHOSE_DELIVERY_STREAM", "test-stream")os.environ.setdefault("METRICS_NAMESPACE", "TerraformPrAgent/Models")os.environ.setdefault("DEFAULT_MODEL", "mistral-large")os.environ.setdefault("MODELS_PARAMETER", "/terraform-pr-agent/models")"""Core test: the real Agent, tools, and execute(), with the Bedrock modelswapped for a scripted FunctionModel so no AWS call is made. The script walksthe loop the post is about: write broken HCL, init, watch validate fail (twice,exercising the raised retry budget), fix it, validate clean, report done. Theruns-bucket upload is exercised against moto, so the real boto3 call path runswithout touching AWS."""
from __future__ import annotations
import jsonimport subprocessimport uuidfrom collections import dequefrom types import SimpleNamespace
import agent.core as coreimport agent.models as modelsimport agent.observability as observabilityimport agent.runs as runsimport boto3import pytestfrom moto import mock_awsfrom opentelemetry.trace import SpanContext, TraceFlagsfrom opentelemetry.trace.status import StatusCodefrom pydantic_ai.messages import ModelMessage, ModelResponse, TextPart, ToolCallPartfrom pydantic_ai.models.bedrock import BedrockConverseModelfrom pydantic_ai.models.function import AgentInfo, FunctionModelfrom pydantic_ai.models.mistral import MistralModel
REGISTRY = { "haiku": { "provider": "bedrock", "model_id": "anthropic.claude-haiku-4-5-20251001-v1:0", "inference_profile_arn": "arn:aws:bedrock:eu-west-1:0:inference-profile/test", }, "mistral-large": {"provider": "mistral", "model_id": "mistral-large-latest"},}
# Captured before the autouse fixture stubs core._build_model, so the# factory tests below can call the real implementation._REAL_BUILD_MODEL = core._build_model
INVALID_TF = 'output "x" { value = var.missing }\n'VALID_TF = 'output "x" { value = "fixed" }\n'
RUNS_BUCKET = "test-runs"
def _stub_model(name: str) -> FunctionModel: # A throwaway model so _build_model makes no SSM call. agent.override in # each test supplies the model actually used; pydantic-ai still requires a # non-None model on the call, so this stands in for that slot. return FunctionModel(lambda messages, info: ModelResponse(parts=[TextPart(content="")]))
@pytest.fixture(autouse=True)def no_observability(monkeypatch) -> None: # The logfire/instrumentation wiring lives in agent.lambda_entry, which the # tests never import, so the Firehose-backed audit processor is never # registered here. _build_model would read the registry from SSM; tests # supply the model through agent.override instead, which takes precedence # over the per-run model. monkeypatch.setattr(core, "_build_model", _stub_model)
@pytest.fixturedef runs_bucket(monkeypatch): # Static stand-in credentials so a hole in the moto mock can never # reach a real account. monkeypatch.setenv("AWS_ACCESS_KEY_ID", "testing") monkeypatch.setenv("AWS_SECRET_ACCESS_KEY", "testing") monkeypatch.setenv("RUNS_BUCKET", RUNS_BUCKET) with mock_aws(): s3 = boto3.client("s3") s3.create_bucket( Bucket=RUNS_BUCKET, CreateBucketConfiguration={"LocationConstraint": "eu-central-1"}, ) yield s3
def scripted_model(steps: deque[list[ToolCallPart]]) -> FunctionModel: def call(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse: if steps: return ModelResponse(parts=list(steps.popleft())) return ModelResponse(parts=[TextPart(content="workspace validated")])
return FunctionModel(call)
def happy_path_steps() -> deque[list[ToolCallPart]]: return deque( [ [ToolCallPart(tool_name="write_file", args={"path": "main.tf", "contents": VALID_TF})], [ToolCallPart(tool_name="terraform_init", args={})], [ToolCallPart(tool_name="terraform_validate", args={})], ] )
def uploaded_keys(s3) -> list[str]: objects = s3.list_objects_v2(Bucket=RUNS_BUCKET).get("Contents", []) return [entry["Key"] for entry in objects]
def test_execute_survives_consecutive_validate_failures(runs_bucket) -> None: steps = deque( [ [ ToolCallPart( tool_name="write_file", args={"path": "main.tf", "contents": INVALID_TF} ) ], [ToolCallPart(tool_name="terraform_init", args={})], # Two failing validates in a row: the default per-tool retry # budget of 1 would kill the run here; Agent(retries=10) is # what lets the loop continue. [ToolCallPart(tool_name="terraform_validate", args={})], [ToolCallPart(tool_name="terraform_validate", args={})], [ ToolCallPart( tool_name="edit_file", args={ "path": "main.tf", "old_string": "var.missing", "new_string": '"fixed"', }, ) ], [ToolCallPart(tool_name="terraform_validate", args={})], ] ) with core.agent.override(model=scripted_model(steps)): result = core.execute("make me a bucket")
assert result.output == "workspace validated" uuid.UUID(result.run_id) assert not steps, "the scripted run should consume every step"
def test_caller_retry_fixes_workspace_after_agent_claims_done(runs_bucket) -> None: # Run 1 leaves an invalid but initialized workspace and claims done while # validate still fails. The caller re-validates, feeds the error back, and # run 2 edits it clean. A TextPart step ends the current run, so the deque # spans two runs rather than draining in one. steps = deque( [ [ ToolCallPart( tool_name="write_file", args={"path": "main.tf", "contents": INVALID_TF} ) ], [ToolCallPart(tool_name="terraform_init", args={})], [TextPart(content="done")], [ ToolCallPart( tool_name="edit_file", args={"path": "main.tf", "old_string": "var.missing", "new_string": '"fixed"'}, ) ], [TextPart(content="fixed it")], ] )
def call(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse: if steps: return ModelResponse(parts=list(steps.popleft())) return ModelResponse(parts=[TextPart(content="done")])
with core.agent.override(model=FunctionModel(call)): result = core.execute("make me a bucket")
assert result.output == "fixed it" assert not steps, "both the first run and the caller-side retry should be consumed"
def test_caller_retry_raises_when_not_converging(runs_bucket) -> None: # The agent sets up an invalid, initialized workspace and never fixes it. # After the retry budget execute raises (Lambda 5xx) and still parks the # broken workspace under status error for debugging. setup = deque( [ [ ToolCallPart( tool_name="write_file", args={"path": "main.tf", "contents": INVALID_TF} ) ], [ToolCallPart(tool_name="terraform_init", args={})], ] )
def call(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse: if setup: return ModelResponse(parts=list(setup.popleft())) return ModelResponse(parts=[TextPart(content="all done")])
with core.agent.override(model=FunctionModel(call)): with pytest.raises(core.ValidateDidNotConverge): core.execute("make me a bucket")
result_key = next(key for key in uploaded_keys(runs_bucket) if key.endswith("/result.json")) parked = json.loads(runs_bucket.get_object(Bucket=RUNS_BUCKET, Key=result_key)["Body"].read()) assert parked["status"] == "error" assert "ValidateDidNotConverge" in parked["error"]
def test_success_uploads_workspace_and_minimal_result(runs_bucket) -> None: with core.agent.override(model=scripted_model(happy_path_steps())): result = core.execute("make me a bucket")
run_id = result.run_id keys = uploaded_keys(runs_bucket) assert f"runs/{run_id}/workspace/main.tf" in keys assert f"runs/{run_id}/result.json" in keys assert not any("/.terraform/" in key for key in keys)
body = runs_bucket.get_object(Bucket=RUNS_BUCKET, Key=f"runs/{run_id}/result.json") assert json.loads(body["Body"].read()) == {"status": "ok"}
def test_failure_still_uploads_with_error_status(runs_bucket) -> None: calls = iter( [[ToolCallPart(tool_name="write_file", args={"path": "main.tf", "contents": VALID_TF})]] )
def call(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse: step = next(calls, None) if step is None: raise RuntimeError("boom") return ModelResponse(parts=list(step))
with core.agent.override(model=FunctionModel(call)): with pytest.raises(RuntimeError, match="boom"): core.execute("make me a bucket")
keys = uploaded_keys(runs_bucket) result_key = next(key for key in keys if key.endswith("/result.json")) run_id = result_key.split("/")[1] assert f"runs/{run_id}/workspace/main.tf" in keys
body = runs_bucket.get_object(Bucket=RUNS_BUCKET, Key=result_key) assert json.loads(body["Body"].read()) == { "status": "error", "error": "RuntimeError('boom')", }
def test_persist_run_requires_bucket(monkeypatch, tmp_path) -> None: # An unset RUNS_BUCKET means the run would never be parked. That is a # deployment fault, so persisting fails fast rather than dropping it. monkeypatch.delenv("RUNS_BUCKET", raising=False) with pytest.raises(RuntimeError, match="RUNS_BUCKET"): runs._persist_run("run-1", tmp_path, status="ok")
def test_run_id_is_the_conversation_id(runs_bucket) -> None: seen: list[str | None] = [] steps = happy_path_steps()
def call(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse: seen.append(messages[0].conversation_id) if steps: return ModelResponse(parts=list(steps.popleft())) return ModelResponse(parts=[TextPart(content="workspace validated")])
with core.agent.override(model=FunctionModel(call)): result = core.execute("make me a bucket")
# The same id the caller gets back is stamped on every model request, # which is what surfaces as gen_ai.conversation.id on the trace. assert seen == [result.run_id] * len(seen)
def test_workspace_files_skips_terraform_dir(tmp_path) -> None: (tmp_path / "main.tf").write_text(VALID_TF) (tmp_path / ".terraform.lock.hcl").write_text("# lock\n") (tmp_path / ".terraform" / "providers").mkdir(parents=True) (tmp_path / ".terraform" / "providers" / "x").write_text("provider blob")
files = [path.relative_to(tmp_path) for path in runs._workspace_files(tmp_path)]
assert sorted(str(path) for path in files) == [".terraform.lock.hcl", "main.tf"]
def test_system_prompt_nudges_provider_constraint_and_lock_file() -> None: assert '"~> 6.0"' in core.SYSTEM_PROMPT assert ".terraform.lock.hcl" in core.SYSTEM_PROMPT
def test_relock_providers_skips_without_lock_file(tmp_path, monkeypatch) -> None: calls: list = [] monkeypatch.setattr(runs.subprocess, "run", lambda *a, **k: calls.append(a)) runs._relock_providers(tmp_path) assert calls == []
def test_relock_providers_covers_all_platforms(tmp_path, monkeypatch) -> None: (tmp_path / ".terraform.lock.hcl").write_text("# lock\n") calls: list[list[str]] = []
def fake_run(args, **kwargs): calls.append(args) return subprocess.CompletedProcess(args, 0, "", "")
monkeypatch.setattr(runs.subprocess, "run", fake_run) runs._relock_providers(tmp_path)
# One terraform call per platform, each carrying only its own -platform flag. assert [args[-1] for args in calls] == [ f"-platform={platform}" for platform in runs._LOCK_PLATFORMS ] for args in calls: assert args[:4] == ["terraform", "providers", "lock", "-no-color"]
def test_relock_providers_continues_after_one_platform_fails(tmp_path, monkeypatch) -> None: (tmp_path / ".terraform.lock.hcl").write_text("# lock\n") calls: list[list[str]] = []
def fake_run(args, **kwargs): calls.append(args) returncode = 1 if f"-platform={runs._LOCK_PLATFORMS[0]}" in args else 0 return subprocess.CompletedProcess(args, returncode, "", "boom")
monkeypatch.setattr(runs.subprocess, "run", fake_run) runs._relock_providers(tmp_path)
assert [args[-1] for args in calls] == [ f"-platform={platform}" for platform in runs._LOCK_PLATFORMS ]
def _sampled_ctx(trace_id: int, span_id: int, *, is_remote: bool = False) -> SpanContext: return SpanContext( trace_id=trace_id, span_id=span_id, is_remote=is_remote, trace_flags=TraceFlags(TraceFlags.SAMPLED), )
def test_audit_processor_ships_on_no_parent() -> None: shipped: list = [] proc = observability.PerTraceAuditProcessor(lambda spans: shipped.append(list(spans))) root = SimpleNamespace(context=_sampled_ctx(1, 1), parent=None) proc.on_end(root) assert shipped == [[root]]
def test_audit_processor_treats_remote_parent_as_local_root() -> None: # instrument_aws_lambda can root the trace at a span propagated in from a # remote parent (API Gateway / X-Ray); is_remote marks it the local root. shipped: list = [] proc = observability.PerTraceAuditProcessor(lambda spans: shipped.append(list(spans))) span = SimpleNamespace(context=_sampled_ctx(1, 2), parent=_sampled_ctx(1, 9, is_remote=True)) proc.on_end(span) assert shipped == [[span]]
def test_audit_processor_buffers_local_child_until_root() -> None: shipped: list = [] proc = observability.PerTraceAuditProcessor(lambda spans: shipped.append(list(spans))) child = SimpleNamespace(context=_sampled_ctx(1, 2), parent=_sampled_ctx(1, 1)) root = SimpleNamespace(context=_sampled_ctx(1, 1), parent=None) proc.on_end(child) assert shipped == [] proc.on_end(root) assert shipped == [[child, root]]
def _agent_span(model: str, *, in_tokens: int = 0, out_tokens: int = 0, errored: bool = False): return SimpleNamespace( attributes={ "metadata": json.dumps({"model": model}), "gen_ai.usage.input_tokens": in_tokens, "gen_ai.usage.output_tokens": out_tokens, }, status=SimpleNamespace(status_code=StatusCode.ERROR if errored else StatusCode.UNSET), start_time=0, end_time=1_000_000, )
def _non_agent_span(): return SimpleNamespace( attributes={"gen_ai.operation.name": "chat"}, status=SimpleNamespace(status_code=StatusCode.UNSET), start_time=0, end_time=1_000_000, )
def test_emit_emf_one_line_per_agent_run(monkeypatch) -> None: records: list = [] monkeypatch.setattr( observability, "log", SimpleNamespace(info=lambda event, **kw: records.append((event, kw))) ) observability._emit_emf([_non_agent_span(), _agent_span("haiku", in_tokens=10, out_tokens=3)]) assert len(records) == 1 event, kw = records[0] assert event == "trace_metrics" assert (kw["Model"], kw["InputTokens"], kw["OutputTokens"], kw["Errors"]) == ("haiku", 10, 3, 0)
def test_emit_emf_emits_per_run_for_retries(monkeypatch) -> None: records: list = [] monkeypatch.setattr( observability, "log", SimpleNamespace(info=lambda event, **kw: records.append((event, kw))) ) observability._emit_emf( [_agent_span("haiku"), _non_agent_span(), _agent_span("mistral-large", errored=True)] ) assert [kw["Model"] for _, kw in records] == ["haiku", "mistral-large"] assert [kw["Errors"] for _, kw in records] == [0, 1]
# These exercise the real _build_model(name) rather than the _stub_model the# autouse fixture installs, guarding the factory's signature and provider# branching (the execute path stubs it, so it cannot catch a signature drift).def test_build_model_selects_bedrock(monkeypatch) -> None: _REAL_BUILD_MODEL.cache_clear() monkeypatch.setattr(models, "fetch_parameter", lambda name: json.dumps(REGISTRY)) model = _REAL_BUILD_MODEL("haiku") assert isinstance(model, BedrockConverseModel) assert model.model_name == "anthropic.claude-haiku-4-5-20251001-v1:0"
def test_build_model_selects_mistral(monkeypatch) -> None: _REAL_BUILD_MODEL.cache_clear() monkeypatch.setattr( models, "fetch_parameter", lambda name: json.dumps(REGISTRY) if "models" in name else "key", ) monkeypatch.setenv("MISTRAL_API_KEY_PARAMETER", "/terraform-pr-agent/mistral-api-key") model = _REAL_BUILD_MODEL("mistral-large") assert isinstance(model, MistralModel) assert model.model_name == "mistral-large-latest""""require_env: the single fail-fast read for required configuration."""
from __future__ import annotations
import pytestfrom agent.env import require_env
def test_returns_value_when_set(monkeypatch) -> None: monkeypatch.setenv("SOME_VAR", "value") assert require_env("SOME_VAR") == "value"
def test_raises_when_unset(monkeypatch) -> None: monkeypatch.delenv("SOME_VAR", raising=False) with pytest.raises(RuntimeError, match="SOME_VAR"): require_env("SOME_VAR")
def test_treats_empty_as_unset(monkeypatch) -> None: monkeypatch.setenv("SOME_VAR", "") with pytest.raises(RuntimeError, match="SOME_VAR"): require_env("SOME_VAR")"""Tests for the Lambda boundary: the INIT wiring and the event envelope.
Importing agent.lambda_entry runs the INIT wiring (configure then wrap), so theside effects are stubbed before a fresh import; the tests assert the wiring andthe envelope, not real logfire configuration."""
from __future__ import annotations
import importlibimport sys
import agent.core as coreimport agent.observability as observabilityimport logfireimport pytest
@pytest.fixturedef lambda_entry(monkeypatch): calls: list = [] monkeypatch.setattr(observability, "configure", lambda: calls.append("configure")) monkeypatch.setattr( logfire, "instrument_aws_lambda", lambda h, **kw: calls.append(("instrument", h)) ) sys.modules.pop("agent.lambda_entry", None) module = importlib.import_module("agent.lambda_entry") module.init_calls = calls return module
def test_configure_runs_before_the_handler_is_wrapped(lambda_entry) -> None: # The container CMD targets agent.lambda_entry.handler, so the wrap must # land on that symbol, with configure() run first. assert lambda_entry.init_calls == ["configure", ("instrument", lambda_entry.handler)]
def test_handler_requires_a_prompt(lambda_entry) -> None: with pytest.raises(ValueError, match="prompt"): lambda_entry.handler({}, None)
def test_handler_runs_the_agent_and_wraps_the_result(lambda_entry, monkeypatch) -> None: seen: dict = {}
def fake_execute(prompt, model=None): seen["prompt"] = prompt seen["model"] = model return core.RunResult(run_id="run-1", model="haiku", output="done")
monkeypatch.setattr(lambda_entry, "execute", fake_execute) response = lambda_entry.handler({"prompt": "make me a bucket", "model": "haiku"}, None)
assert seen == {"prompt": "make me a bucket", "model": "haiku"} assert response == { "status": "ok", "run_id": "run-1", "model": "haiku", "output": "done", }"""Tests for the workspace tools: path guards, init/validate semantics,and how ModelRetry interacts with pydantic-ai's per-tool retry budget."""
from __future__ import annotations
from pathlib import Pathfrom types import SimpleNamespace
import pytestfrom agent.tools import ( WorkspaceDeps, read_file, terraform_init, terraform_validate, write_file,)from pydantic_ai import Agent, ModelRetryfrom pydantic_ai.exceptions import UnexpectedModelBehaviorfrom pydantic_ai.messages import ModelMessage, ModelResponse, ToolCallPartfrom pydantic_ai.models.function import AgentInfo, FunctionModel
VALID_TF = 'output "ok" { value = "ok" }\n'# Parses fine (init passes) but references an undeclared variable, so the# failure surfaces at the validate step.INVALID_TF = 'output "x" { value = var.missing }\n'
def ctx_for(root: Path) -> SimpleNamespace: # The tools only touch ctx.deps, so a namespace stands in for the # full RunContext. return SimpleNamespace(deps=WorkspaceDeps(root=root))
def test_read_missing_file_raises_model_retry(tmp_path: Path) -> None: with pytest.raises(ModelRetry, match="must be a file"): read_file(ctx_for(tmp_path), "absent.tf")
def test_path_escape_raises_model_retry(tmp_path: Path) -> None: with pytest.raises(ModelRetry, match="workspace root"): write_file(ctx_for(tmp_path), "../outside.tf", "boom")
def test_init_then_validate_passes(tmp_path: Path) -> None: ctx = ctx_for(tmp_path) (tmp_path / "main.tf").write_text(VALID_TF) assert terraform_init(ctx) == "OK: terraform init completed." assert terraform_validate(ctx) == "OK: terraform validate passed."
def test_init_failure_raises_model_retry(tmp_path: Path) -> None: (tmp_path / "main.tf").write_text("terraform {") with pytest.raises(ModelRetry, match="terraform init failed"): terraform_init(ctx_for(tmp_path))
def test_validate_failure_raises_model_retry(tmp_path: Path) -> None: ctx = ctx_for(tmp_path) (tmp_path / "main.tf").write_text(INVALID_TF) terraform_init(ctx) with pytest.raises(ModelRetry, match="terraform validate failed"): terraform_validate(ctx)
def test_requirements_added_mid_run_recover_via_init(tmp_path: Path) -> None: """The flow the agent is prompted to follow: adding a module after the first init breaks validate until terraform_init runs again.""" ctx = ctx_for(tmp_path) (tmp_path / "main.tf").write_text(VALID_TF) terraform_init(ctx) assert terraform_validate(ctx) == "OK: terraform validate passed."
mod = tmp_path / "mod" mod.mkdir() (mod / "main.tf").write_text(VALID_TF) (tmp_path / "uses_module.tf").write_text('module "m" { source = "./mod" }\n')
with pytest.raises(ModelRetry, match="terraform init"): terraform_validate(ctx) terraform_init(ctx) assert terraform_validate(ctx) == "OK: terraform validate passed."
def _always_validate_agent(retries: int | None) -> Agent: def always_validate(messages: list[ModelMessage], info: AgentInfo) -> ModelResponse: return ModelResponse(parts=[ToolCallPart(tool_name="terraform_validate", args={})])
kwargs = {} if retries is None else {"retries": retries} return Agent( FunctionModel(always_validate), deps_type=WorkspaceDeps, tools=[terraform_init, terraform_validate], **kwargs, )
def test_default_budget_kills_run_on_second_consecutive_failure(tmp_path: Path) -> None: """pydantic-ai counts consecutive ModelRetry failures per tool against `retries` (default 1) and then raises UnexpectedModelBehavior. This is why handler.py sets a higher budget.""" (tmp_path / "main.tf").write_text("terraform {") agent = _always_validate_agent(retries=None) with pytest.raises(UnexpectedModelBehavior, match="exceeded max retries"): agent.run_sync("go", deps=WorkspaceDeps(root=tmp_path))
def test_raised_budget_tolerates_consecutive_failures(tmp_path: Path) -> None: (tmp_path / "main.tf").write_text("terraform {") agent = _always_validate_agent(retries=5) with pytest.raises(UnexpectedModelBehavior, match="exceeded max retries count of 5"): agent.run_sync("go", deps=WorkspaceDeps(root=tmp_path))# Keep the build context to what the Dockerfile actually copies; .envrc# files stay out because they can hold tokens..venvbuild.gitinfrascriptstests.envrc.envrc.local*.tar.gzagent/handler.pytests/test_handler.py# Multi-stage build: the builder stages below carry tooling (unzip, uv,# rpm metadata) that the function never needs at runtime. Only their# outputs are copied into the final stage, so the shipped image stays# lean and pulls faster on a cold start.
FROM public.ecr.aws/lambda/python:3.13 AS terraform# Pinned + checksum-verified so the image build is reproducible and a# tampered release archive fails the build instead of shipping.ARG TERRAFORM_VERSION=1.15.6RUN dnf install -y unzip && dnf clean allRUN curl -fsSLO https://releases.hashicorp.com/terraform/${TERRAFORM_VERSION}/terraform_${TERRAFORM_VERSION}_linux_arm64.zip \ && curl -fsSLO https://releases.hashicorp.com/terraform/${TERRAFORM_VERSION}/terraform_${TERRAFORM_VERSION}_SHA256SUMS \ && grep " terraform_${TERRAFORM_VERSION}_linux_arm64.zip\$" terraform_${TERRAFORM_VERSION}_SHA256SUMS | sha256sum -c - \ && unzip terraform_${TERRAFORM_VERSION}_linux_arm64.zip -d /usr/local/bin \ && rm terraform_${TERRAFORM_VERSION}_linux_arm64.zip terraform_${TERRAFORM_VERSION}_SHA256SUMS
# Same uv flow as the zip build this replaces (see the uv AWS Lambda# guide); the dependency set installs straight into the task root, where# the final stage picks it up.FROM public.ecr.aws/lambda/python:3.13 AS pythonCOPY --from=ghcr.io/astral-sh/uv:0.11.21 /uv /usr/local/bin/uvWORKDIR /opt/buildCOPY pyproject.toml uv.lock ./RUN uv export --frozen --no-dev --no-editable -o requirements.txt \ && uv pip install \ --no-installer-metadata \ --no-compile-bytecode \ --target "${LAMBDA_TASK_ROOT}" \ -r requirements.txt
# Container images cannot attach layers, so the Lambda Insights extension# is baked into the image: pinned version, detached GPG signature checked# against the key fingerprint published in the Lambda Insights docs, so a# tampered rpm fails the build.FROM public.ecr.aws/lambda/python:3.13 AS insightsARG INSIGHTS_VERSION=1.0.660.0ARG INSIGHTS_BASE_URL=https://lambda-insights-extension-arm64.s3-ap-northeast-1.amazonaws.com# The downloaded key is checked against the fingerprint from the docs# before anything trusts it; gpg runs with --batch/--no-tty/--no-autostart# because the base image ships no gpg-agent.RUN curl -fsSLO ${INSIGHTS_BASE_URL}/amazon_linux/lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm \ && curl -fsSLO ${INSIGHTS_BASE_URL}/amazon_linux/lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm.sig \ && curl -fsSLO ${INSIGHTS_BASE_URL}/lambda-insights-extension.gpg \ && gpg --batch --no-tty --show-keys --with-colons lambda-insights-extension.gpg \ | grep -q '^fpr:::::::::E0AFFA11FFF35BD7349EE222479C97A1848ABDC8:' \ && gpg --batch --no-tty --no-autostart --import lambda-insights-extension.gpg \ && gpg --batch --no-tty --no-autostart --verify \ lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm.sig \ lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm \ && rpm -U lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm \ && rm -f lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm* lambda-insights-extension.gpg
# The shipped image: only the artifacts the function uses at runtime# cross over from the builder stages.FROM public.ecr.aws/lambda/python:3.13COPY --from=terraform /usr/local/bin/terraform /usr/local/bin/terraformCOPY --from=insights /opt/extensions /opt/extensionsCOPY --from=insights /opt/cloudwatch /opt/cloudwatchCOPY --from=python ${LAMBDA_TASK_ROOT} ${LAMBDA_TASK_ROOT}COPY agent ${LAMBDA_TASK_ROOT}/agentWORKDIR ${LAMBDA_TASK_ROOT}
# terraform needs a writable HOME for incidental state; /tmp is the only# writable path at runtime. CMD replaces the zip package's handler attribute# and points at lambda_entry, the instrumented entry point, not the bare# handler module.ENV HOME=/tmp \ TF_IN_AUTOMATION=true \ TF_INPUT=falseCMD ["agent.lambda_entry.handler"][project]name = "terraform-pr-agent"version = "0.1.0"description = "The terraform-pr-agent Lambda handler."requires-python = ">=3.13"dependencies = [ "pydantic-ai-slim[bedrock,mistral,retries]>=1.106", "logfire[aws-lambda]>=4.35", "structlog>=24", "boto3>=1.35",]
[dependency-groups]dev = [ "pytest>=8", "moto[s3]>=5",]
[tool.pytest.ini_options]testpaths = ["tests"]pythonpath = ["."]# terraform-pr-agent
A pydantic-ai agent that writes and validates Terraform, running as acontainer-image AWS Lambda. This is the worked example from the **Terraform PRAgent** series; each post adds one capability.
Series: <https://andreaslang.dev/posts/terraform-pr-agent/>
At this checkpoint the agent gets a `/tmp` workspace, sandboxed file tools(list, read, write, edit, delete), and a `terraform_validate` tool it can callin a loop. It ships as a Docker-based Lambda with the terraform CLI baked in.
## Prerequisites
- [uv](https://docs.astral.sh/uv/) for Python and the single-file scripts- Terraform 1.x- Docker with buildx (the image is arm64; the placeholder is built during apply)- An AWS account you are happy to create resources in. A throwaway sandbox sub-account is assumed; never point this at production. Credentials via `aws configure sso` or static keys.- Bedrock model access enabled for the models in `infra/models.tf`, in your region- Optional: a [Logfire](https://logfire.pydantic.dev/) token for tracing, and a [Mistral API key](https://console.mistral.ai/api-keys/) for the Mistral models
## Setup
A commented `.envrc.local` template ships in the scaffold (gitignored). Fill itin and load it:
```bashdirenv allow```
At minimum set `AWS_REGION`, your AWS credentials, and `TF_VAR_alert_email`(AWS emails a confirmation for the alarm topic). The Logfire and Mistral keysare optional; leave them unset to skip those integrations. A few values(`AUDIT_BUCKET`, `AGENT_ROLE_ARN`, and friends) come from terraform outputs, soset them and run `direnv reload` after the first apply.
If you skip the Mistral key, set `TF_VAR_default_model=haiku` (a Bedrock entryin `infra/models.tf`); the default is `mistral-large`, which needs the key.
## Deploy
```bashcd infraterraform initterraform planterraform applycd .../scripts/build-lambda.sh```
`terraform apply` stands the function up on a placeholder image so everyresource is created in one pass; `build-lambda.sh` then builds the real arm64image and points the Lambda at it. Re-run the script whenever you change`agent/` or its dependencies.
Never blind-apply: read the plan first, and note the apply reads your`.envrc.local` env (the alert email and the optional tokens feed `TF_VAR_*`).
## Run the agent
Invoke the function with an empty payload (it falls back to a sample prompt) oryour own:
```bashaws lambda invoke --function-name terraform-pr-agent \ --payload '{"prompt": "Set up a new terraform project, creating a best practice s3 bucket."}' \ --cli-binary-format raw-in-base64-out --cli-read-timeout 0 out.jsoncat out.json```
`--cli-read-timeout 0` disables the CLI's default 60s read timeout: asynchronous invoke runs the whole agent, which takes tens of seconds.
A `model` field in the payload overrides the `default_model` variable. Each runwrites its workspace and a `result.json` to the runs bucket under`runs/<run_id>/`, and emits a trace (Logfire if configured, plus the S3 auditcopy). The CloudWatch dashboard `terraform-pr-agent` shows the model and Lambdametrics.
## Tests
```bashuv syncuv run pytest```
The suite is moto-backed and makes no real AWS calls.
## Layout
- `agent/` pydantic-ai handler and tools (the Lambda code)- `infra/` Terraform for all AWS resources- `scripts/` standalone PEP 723 scripts (`uv run scripts/<name>.py`) plus `build-lambda.sh`- `tests/` pytest suite
See `AGENTS.md` for the conventions used when editing this project.Fast-forward to the final code of this post
Download the cumulative checkpoint that matches the state at the end of this post. Useful for landing on the finished tree without working through every step.
mkdir -p ~/projectscd ~/projectscurl -fsSL https://andreaslang.dev/terraform-pr-agent/terraform-pr-agent-04.tar.gz | tar xzFrom zip to container image
In previous posts we used a normal Python Lambda, but for this post we moved to a Docker based Lambda to avoid the Lambda 250 MB size limit (unzipped). We could still have managed in this post with terraform 108 MB + site-packages 56 MB = 164 MB, but the container ceiling is 10 GB rather than 250 MB, which buys real headroom as the image grows. The container also hands us the whole image to control, system packages and filesystem layout, not just Python deps layered onto the AWS runtime. As a bonus it is a standard Docker image, so moving to something like ECS Fargate later is straightforward.
Looking at the Docker image you will also notice we use a multi-stage build, where we have build layers of the image in multiple stages and then copy them into the final image. This is an easy way of keeping build tools out of the final image and therefore reducing the size of the image. Our final image is 739 MB total, 169 MB above the shared 570 MB base. That sounds huge for people trying to build small images, but the base image we use is the AWS Lambda Python base image, which is heavily cached across the Lambda stack. So in practice we only pull the final 169 MB layer, which is far more reasonable.
builder stage copied into the final image------------- ---------------------------terraform --> terraform binarypython --> site-packages (/var/task)insights --> Lambda Insights extensionbuild context --> agent/ source
base image: public.ecr.aws/lambda/python:3.13left in the builders, never shipped: unzip, dnf cache, uv, gpg keyring, rpm metadataWe will not go through all the stages of the image, but here are the Python dependencies as an example. We use the AWS Lambda Python base image, install uv by copying the layer from yet another Docker image, copy pyproject.toml/uv.lock, export to a requirements.txt and then run uv pip to install the dependencies.
# Same uv flow as the zip build this replaces (see the uv AWS Lambda# guide); the dependency set installs straight into the task root, where# the final stage picks it up.FROM public.ecr.aws/lambda/python:3.13 AS pythonCOPY --from=ghcr.io/astral-sh/uv:0.11.21 /uv /usr/local/bin/uvWORKDIR /opt/buildCOPY pyproject.toml uv.lock ./RUN uv export --frozen --no-dev --no-editable -o requirements.txt \ && uv pip install \ --no-installer-metadata \ --no-compile-bytecode \ --target "${LAMBDA_TASK_ROOT}" \ -r requirements.txtThe Python stage does not ship. The final stage below just assembles the image by copying all the previous layers into it. Here you see we use:
- The Terraform binary
- The Lambda Insights extension (extensions and cloudwatch)
- The Python dependencies
- Our agent code
Initially I considered baking the Terraform AWS provider into the image, but managing it properly turned out to be difficult without constraining the use case further than it already is. So I took the simpler route: download the providers every time the agent calls terraform init.
# The shipped image: only the artifacts the function uses at runtime# cross over from the builder stages.FROM public.ecr.aws/lambda/python:3.13COPY --from=terraform /usr/local/bin/terraform /usr/local/bin/terraformCOPY --from=insights /opt/extensions /opt/extensionsCOPY --from=insights /opt/cloudwatch /opt/cloudwatchCOPY --from=python ${LAMBDA_TASK_ROOT} ${LAMBDA_TASK_ROOT}COPY agent ${LAMBDA_TASK_ROOT}/agentWORKDIR ${LAMBDA_TASK_ROOT}The CMD attribute for a Docker based Lambda needs to be the Python handler. It points at the handler function in
the agent.lambda_entry module. While we are at it we also make terraform non-interactive and set the home folder to the
only writable folder in a Lambda (/tmp).
# terraform needs a writable HOME for incidental state; /tmp is the only# writable path at runtime. CMD replaces the zip package's handler attribute# and points at lambda_entry, the instrumented entry point, not the bare# handler module.ENV HOME=/tmp \ TF_IN_AUTOMATION=true \ TF_INPUT=falseCMD ["agent.lambda_entry.handler"]ECR and the placeholder image
A consequence of switching to a Docker based Lambda is that we now need a placeholder image to avoid the terraform
apply needing a three step process (first creating the ECR repo, pushing the image, then creating the Lambda).
With the placeholder in place, a single apply can create the function, and scripts/build-lambda.sh pushes the real
image afterward. It keeps the terraform apply self-contained, with the code ship as a separate step.
# Container twin of the zip flow's archive_file placeholder: the function# resource needs a pullable image at create time, so terraform seeds a# minimal one. Create-only (input never changes), so scripts/build-lambda.sh# owns every push after this.resource "terraform_data" "placeholder_image" { input = aws_ecr_repository.agent.repository_url
# Needs docker and the aws cli on the machine running apply; both are # already prerequisites for the series. provisioner "local-exec" { command = <<-EOT aws ecr get-login-password --region ${data.aws_region.current.region} | docker login --username AWS --password-stdin ${split("/", aws_ecr_repository.agent.repository_url)[0]} docker buildx build --platform linux/arm64 --provenance=false \ -t ${aws_ecr_repository.agent.repository_url}:placeholder \ --push ${path.module}/placeholder EOT }}For the Lambda itself, package_type = "Image" and image_uri switch it to a Docker based Lambda. We also tell
terraform to ignore changes to image_uri, because otherwise a re-apply would reset the function back to the
placeholder image. Instead we want our agent Docker build to have control over the image URI. Further, we tweak
timeout, memory size, and ephemeral storage to match the heavier resource needs now that terraform runs inside the
function. Lambda layers, which we used in a previous post, are removed entirely; they do not work with a Docker based
Lambda.
resource "aws_lambda_function" "agent" { function_name = "terraform-pr-agent" role = aws_iam_role.lambda.arn architectures = ["arm64"]
# The handler entry point comes from the image's CMD; the runtime, # handler, and layers attributes only apply to zip packages. package_type = "Image" image_uri = "${aws_ecr_repository.agent.repository_url}:placeholder"
11 collapsed lines
# Max Memory Used overstates what this function needs. It runs to ~2 GB on a # heavy run, but the track_memory spans (see agent/memory.py) show the real, # non-reclaimable demand stays under ~1 GB: ~315 MB resident for the Python # runtime plus a transient ~420 MB while terraform validate loads the # provider schema. The rest is reclaimable page cache from the ~800 MB # provider download and re-lock unpacks doing file IO on /tmp, which the # cgroup-based billed figure counts but the kernel drops under pressure, so # it is not OOM risk. Memory is therefore not the binding constraint here. # 3008 is set for the vCPU it buys, not the RAM: above 1769 MB Lambda gives a # full core (3008 is ~1.7), which speeds the run. Drop it toward ~1769 if # latency matters less than cost; do not raise it for memory headroom. memory_size = 3008
# The per-run tool budget is the runaway guard; the timeout only has to # accommodate several model turns with init + validate rounds in between. timeout = 300
# Two things land in /tmp: terraform init downloads the AWS provider # (~800 MB) into the workspace, and the post-run re-lock unpacks the # provider for three platforms (another ~2 GB) to write a portable lock # file. 4 GB covers both with headroom; the default 512 MB would not. ephemeral_storage { size = 4096 }
tracing_config { mode = "Active" }
17 collapsed lines
environment { variables = merge( { MODELS_PARAMETER = aws_ssm_parameter.models.name DEFAULT_MODEL = var.default_model METRICS_NAMESPACE = local.metrics_namespace FIREHOSE_DELIVERY_STREAM = aws_kinesis_firehose_delivery_stream.audit.name RUNS_BUCKET = aws_s3_bucket.runs.bucket }, local.logfire_token_wired ? { LOGFIRE_TOKEN_PARAMETER = local.logfire_token_parameter_name } : {}, local.mistral_key_wired ? { MISTRAL_API_KEY_PARAMETER = aws_ssm_parameter.mistral_api_key[0].name } : {}, ) }
# Code ships out of band: scripts/build-lambda.sh pushes a new image and # calls update-function-code, so terraform must not flip the function # back to the placeholder on the next apply. lifecycle { ignore_changes = [image_uri] }
depends_on = [ aws_iam_role_policy_attachment.lambda_basic_execution, aws_iam_role_policy_attachment.lambda_insights, aws_iam_role_policy.lambda_permissions, terraform_data.placeholder_image, ]}Watching cold starts
One common downside of a Docker Lambda is that cold starts are slower than normal Lambdas. We do not particularly care about cold starts, but we do want to measure them and make sure they do not get out of hand due to dependency bloat. The AWS Lambda Insights extension is a good way to measure cold starts, but because we cannot use layers, we need to add it to the image. The code looks scary, and I wish AWS thought about the end user the way Astral/uv do, but it is taken straight from the AWS docs.
# Container images cannot attach layers, so the Lambda Insights extension# is baked into the image: pinned version, detached GPG signature checked# against the key fingerprint published in the Lambda Insights docs, so a# tampered rpm fails the build.FROM public.ecr.aws/lambda/python:3.13 AS insightsARG INSIGHTS_VERSION=1.0.660.0ARG INSIGHTS_BASE_URL=https://lambda-insights-extension-arm64.s3-ap-northeast-1.amazonaws.com# The downloaded key is checked against the fingerprint from the docs# before anything trusts it; gpg runs with --batch/--no-tty/--no-autostart# because the base image ships no gpg-agent.RUN curl -fsSLO ${INSIGHTS_BASE_URL}/amazon_linux/lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm \ && curl -fsSLO ${INSIGHTS_BASE_URL}/amazon_linux/lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm.sig \ && curl -fsSLO ${INSIGHTS_BASE_URL}/lambda-insights-extension.gpg \ && gpg --batch --no-tty --show-keys --with-colons lambda-insights-extension.gpg \ | grep -q '^fpr:::::::::E0AFFA11FFF35BD7349EE222479C97A1848ABDC8:' \ && gpg --batch --no-tty --no-autostart --import lambda-insights-extension.gpg \ && gpg --batch --no-tty --no-autostart --verify \ lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm.sig \ lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm \ && rpm -U lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm \ && rm -f lambda-insights-extension-arm64.${INSIGHTS_VERSION}.rpm* lambda-insights-extension.gpgThe extension needs one IAM grant to write to its /aws/lambda-insights log group, a single managed-policy
attachment that sits in the file browser above.
Below you see how we wire the metrics into the dashboard. We take the Lambda Insights metrics and plot:
- avg duration and max duration in ms
- function memory used
/tmpstorage space used
46 collapsed lines
{ type = "text" x = 0 y = 0 width = 24 height = 2 properties = { markdown = "## Lambda\nContainer-image function health: invocations and errors, end to end duration, cold start init duration (Lambda Insights emits `init_duration` only on a cold start), and the memory and `/tmp` footprint behind the `memory_size` and `ephemeral_storage` sizing." } }, { type = "metric" x = 0 y = 2 width = 12 height = 6 properties = { title = "Lambda invocations and errors" region = local.cloudwatch_region view = "timeSeries" stat = "Sum" period = 60 metrics = [ ["AWS/Lambda", "Invocations", "FunctionName", local.lambda_name, { label = "${local.lambda_name} / invocations" }], [".", "Errors", ".", ".", { label = "${local.lambda_name} / errors" }], [".", "Throttles", ".", ".", { label = "${local.lambda_name} / throttles" }], ] } }, { type = "metric" x = 12 y = 2 width = 12 height = 6 properties = { title = "Lambda duration (ms)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ ["AWS/Lambda", "Duration", "FunctionName", local.lambda_name, { label = "${local.lambda_name} / avg", stat = "Average" }], [".", ".", ".", ".", { label = "${local.lambda_name} / p99", stat = "p99" }], ] } }, { type = "metric" x = 0 y = 8 width = 12 height = 6 properties = { title = "Cold start init duration (ms)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ # Insights reports init_duration only when an init phase happened, # so points appear only on cold starts. ["LambdaInsights", "init_duration", "function_name", local.lambda_name, { label = "${local.lambda_name} / init avg (ms)", stat = "Average" }], [".", ".", ".", ".", { label = "${local.lambda_name} / init max (ms)", stat = "Maximum" }], ] } }, { type = "metric" x = 12 y = 8 width = 12 height = 6 properties = { title = "Memory used (MB)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ # used_memory_max is the cgroup figure (Max Memory Used), which # counts the reclaimable /tmp page cache and so reads ~2 GB while # real demand is under 1 GB. Backs the memory_size comment in # lambda.tf. ["LambdaInsights", "used_memory_max", "function_name", local.lambda_name, { label = "${local.lambda_name} / memory max (MB)", stat = "Maximum" }], ] } }, { type = "metric" x = 0 y = 14 width = 12 height = 6 properties = { title = "/tmp used (bytes)" region = local.cloudwatch_region view = "timeSeries" period = 60 metrics = [ # tmp_used tracks the ~800 MB provider download into /tmp, behind # the 4 GB ephemeral_storage sizing in lambda.tf. ["LambdaInsights", "tmp_used", "function_name", local.lambda_name, { label = "${local.lambda_name} / tmp used (B)", stat = "Maximum" }], ] } },In CloudWatch the dashboard looks like this. Cold starts sit around 3s, acceptable for our use case, and the memory
and /tmp metrics stay within the configured limits.
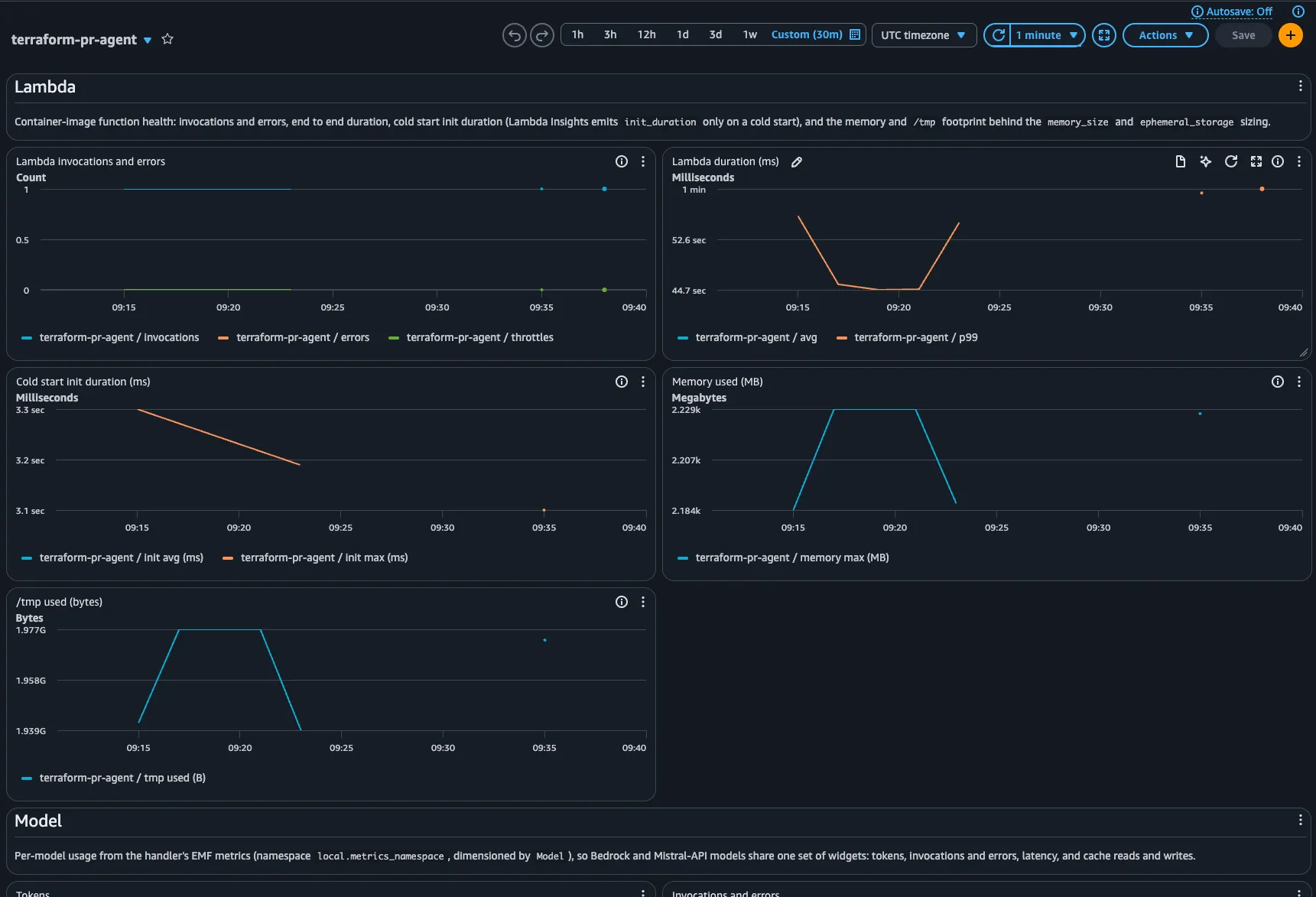
Workspace setup
The agent needs some context for the run. Pydantic-ai is itself stateless. The agent only has conversation history
if the previous messages are passed to it as a message_history argument. We talked about this back in post 1. Here
we also need to give the agent context about the workspace it is working in so that the root/project folder can be
validated. Tool calls should usually just use a relative path to it, but we need to make sure everything ends up in
this tmp folder, so we can pick up the end result of the agent’s work. You also see files_read there; we use it to
stop the agent editing files it has not read.
class WorkspaceDeps(BaseModel): """Per-run dependencies threaded through ``RunContext``.
``root`` is the directory the agent is allowed to read, write, and validate inside. Tools resolve every path relative to it and reject anything that escapes the root, so the agent cannot reach outside the workspace via ``..`` or absolute paths. """
model_config = ConfigDict(arbitrary_types_allowed=True)
root: Path files_read: set[Path] = Field(default_factory=set)Each time the LLM invokes any of our tools with a path we validate it against the workspace root. Luckily Python has
the pathlib module that makes this easy.
def _resolve_absolute_path(ctx: RunContext[WorkspaceDeps], path: str): root = ctx.deps.root.resolve() absolute_path = (root / Path(path)).resolve() if not absolute_path.is_relative_to(root): raise ModelRetry( f"Path {path} must be relative to the workspace root, " f"it cannot be absolute or walk up the directory tree." ) return absolute_pathFile tools
We have list_files(path), read_file(path), write_file(path, contents), edit_file(path, old_string, new_string)
and delete_file(path). We won’t go through all of them, but show you the edit file tool. It uses
_resolve_absolute_path(ctx, path) to resolve the path (always absolute in the end), which will also verify that
the path is inside the workspace root. Then it validates additional constraints:
- The file exists
- The agent has previously read or created the file
old_string(string to replace) is in the file contentsold_stringonly exists once in the file contents (prevents accidental replacements)
One decision worth calling out: we raise ModelRetry instead of returning a description of the mistake the agent makes. The difference is that ModelRetry counts against the tool retry budget of the agent, while a string description telling the agent what to do next does not. It avoids long chains of corrections costing too many tokens. If that happens we would rather fail and raise an alert in a production environment, so that an SRE or the product team can investigate and fix the cause of the agent’s confusion (better system prompt or tool descriptions). During initial validation it also allows you to weed out models that are not as good with tool calls, which makes them unsuitable for your task.
def edit_file( ctx: RunContext[WorkspaceDeps], path: str, old_string: str, new_string: str,) -> None: """Replace ``old_string`` with ``new_string`` in the file at ``path``.""" file = _resolve_absolute_file(ctx, path) if not file.exists(): raise ModelRetry(f"File {path} does not exist.") if file not in ctx.deps.files_read: raise ModelRetry(f"File {path} was not read. If you want to edit it, then read it first.") with file.open("r+") as f: contents = f.read() if old_string not in contents: raise ModelRetry(f"String {old_string} not found in file {path}.") if contents.count(old_string) > 1: raise ModelRetry(f"String {old_string} found more than once in file {path}.") f.seek(0) f.write(contents.replace(old_string, new_string)) f.truncate()The validate tool: agent-driven, any time
In this blog post we only offer terraform_validate() and terraform_init() to the agent to interact and validate
terraform code. Terraform validate for example has a very simple flow:
- Use a sub-process to run
terraform validate - Validate the result:
- If the exit code is 0 (success) return OK message
- If the exit code is 1 (failure) ModelRetry error with stdout and stderr
def _validate(root: Path) -> tuple[bool, str]: """Run ``terraform validate`` in ``root``; return (passed, combined output).
The agent reaches this through the tool below; the caller-side retry in handler.py calls it directly to re-check the workspace after the run. """ with track_memory("terraform_validate"): result = subprocess.run( ["terraform", "validate", "-no-color"], cwd=root, capture_output=True, text=True, ) return result.returncode == 0, f"{result.stdout}{result.stderr}"
def terraform_validate(ctx: RunContext[WorkspaceDeps]) -> str: """Run ``terraform validate`` in the workspace and return its output.""" ok, output = _validate(ctx.deps.root) if ok: return "OK: terraform validate passed." raise ModelRetry(f"terraform validate failed:\n{output}")A little bonus is the track_memory decorator, which creates a new span and attaches memory information to it. So we
can dive into the agent run in Logfire and see how much memory it used.
This is the Agent definition, one instance reused across invocations. The error budget for ModelRetry can be configured in the Agent setup.
32 collapsed lines
# A soft reproducibility nudge following the standard Terraform pattern: a# version constraint in the config, the exact version and checksums in the lock# file. The tool-call spans in the trace are the ground truth for what the agent# actually wrote._PROVIDER_PIN_RULE = ( "When you add the AWS provider, give it a version constraint such as " '"~> 6.0" rather than leaving it unconstrained. terraform init records ' "the exact resolved version and checksums in .terraform.lock.hcl, " "which travels with the workspace and is the reproducibility record, " "so the constraint does not need to be an exact pin. Pin an exact " "version only when the user asks for one. Example:\n" "\n" "terraform {\n" " required_providers {\n" " aws = {\n" ' source = "hashicorp/aws"\n' ' version = "~> 6.0"\n' " }\n" " }\n" "}")
SYSTEM_PROMPT = ( "You are the terraform-pr-agent. You operate on a Terraform workspace " "through file tools (list_files, read_file, write_file, edit_file, " "delete_file) and two terraform tools. Use the file tools to explore, " "write, and edit. Run terraform_init before your first validate and " "again whenever you add or change provider or module requirements. " "Call terraform_validate after you write or change files to confirm " "the workspace still parses; treat its output as feedback and edit " "until it is clean.\n\n" + _PROVIDER_PIN_RULE)
# One Agent instance is reused across invocations: the tools reach the workspace# through RunContext.deps, so each run_sync scopes them to a fresh WorkspaceDeps.# The model carries no default; it is built from the registry at INVOKE and# passed per run, so switching DEFAULT_MODEL needs no code change.agent = Agent( deps_type=WorkspaceDeps, system_prompt=SYSTEM_PROMPT, tools=[ list_files, read_file, write_file, edit_file, delete_file, terraform_init, terraform_validate, ], # Tools raise ModelRetry on failure; pydantic-ai ends the run once one tool # fails more than `retries` times in a row (a success resets the count). The # default of 1 would end the run on the second straight failing validate, # which is a normal part of the write-validate-edit loop, so the budget is # raised well past anything a converging run produces. The per-run turn cap # stays the runaway guard. retries=10,)Caller-side retry
Working with LLMs reminds me of the German saying:
Vertrauen ist gut, Kontrolle ist besser (Trust is good, verifying is better)
Here the agent can in principle ignore every instruction and report success while nothing actually works. Hence, we add
some deterministic checks in the end and feed message_history back to the agent with a new prompt if they fail. At this
stage this is really just making sure terraform init does not fail.
# The agent can report done while terraform validate still fails. # Re-validate ourselves and feed any error back as a follow-up turn, # reusing the run id and message history so each retry is an # invoke_agent span under the one invocation trace. Give up after the # budget and raise so the failure is honest rather than a clean run # over a broken workspace. ok, output = _validate(root) attempts = 0 while not ok and attempts < _MAX_VALIDATE_RETRIES: attempts += 1 result = agent.run_sync( _RETRY_PROMPT.format(output=output), deps=deps, conversation_id=run_id, model=built, message_history=result.all_messages(), metadata={"model": model_name}, ) ok, output = _validate(root) if not ok: raise ValidateDidNotConverge(output)Parking the output in S3
In this iteration of the code we do not yet integrate GitHub, so to be able to see the code that the agent produced,
we need to store it somewhere. This code stores it in an S3 bucket so we can inspect it later. We skip the
.terraform folder, which is just local init scratch.
def _persist_run(run_id: str, workspace: Path, status: str, error: str | None = None) -> None:6 collapsed lines
"""Park the workspace and a minimal result marker under runs/<run_id>/.
result.json carries only what the audit trace does not: prompt, output, and messages already live in the trace under the same conversation id, so copying them here would create a second source of truth. """ bucket = require_env("RUNS_BUCKET") s3 = boto3.client("s3") for file in _workspace_files(workspace): key = f"runs/{run_id}/workspace/{file.relative_to(workspace)}" s3.put_object(Bucket=bucket, Key=key, Body=file.read_bytes()) result = {"status": status} | ({"error": error} if error else {}) s3.put_object( Bucket=bucket, Key=f"runs/{run_id}/result.json", Body=json.dumps(result).encode(), )
def _workspace_files(workspace: Path) -> Iterator[Path]:4 collapsed lines
"""Every file except .terraform/, which is init scratch plus the provider downloaded into /tmp, gigabytes of noise per run. The top-level .terraform.lock.hcl is the reproducibility record and stays. """ for path in sorted(workspace.rglob("*")): if ".terraform" in path.relative_to(workspace).parts: continue if path.is_file(): yield pathTracing the whole invocation
The Lambda entry point stays thin: it requires a prompt, hands off to core.execute, and shapes the response. Its other
job is the INIT wiring, configure telemetry then wrap the handler, which has to run at import. Keeping the execution
logic separate from anything Lambda-related also means we could add other entry points later, deploying this somewhere
else (e.g. ECS Fargate).
"""The Lambda boundary: parse the event, run the agent, shape the response.
This module also owns the INIT wiring. The container CMD targetsagent.lambda_entry.handler, so a unit test that imports agent.core neverconfigures logfire or registers the Firehose audit processor. EverythingLambda-specific lives here, off the core, which is why no runtime-detectioncheck is needed to keep it out of tests."""
from __future__ import annotations
from typing import NotRequired, TypedDict
import logfire
from agent import observabilityfrom agent.core import execute
10 collapsed lines
class HandlerEvent(TypedDict): prompt: str model: NotRequired[str]
class HandlerResponse(TypedDict): status: str run_id: str model: str output: str
def handler(event: HandlerEvent, context: object) -> HandlerResponse: """Lambda entry point: require a prompt, run the agent, wrap the result.
``prompt`` is required; an event without one is a caller error and fails fast rather than running a default. ``model`` overrides DEFAULT_MODEL when given. A run that does not converge raises, so the Lambda reports 5xx and the workspace ships under status error for debugging. """ prompt = event.get("prompt") if not prompt: raise ValueError("event missing required 'prompt'") result = execute(prompt, event.get("model")) return { "status": "ok", "run_id": result.run_id, "model": result.model, "output": result.output, }
def bootstrap() -> None: """Stand up telemetry, then attach the Lambda runtime adapter.
configure() first so the tracer provider exists when the handler is wrapped. instrument_aws_lambda wraps the target named by _HANDLER (agent.lambda_entry.handler) in place, so each invocation becomes one trace. """ observability.configure() logfire.instrument_aws_lambda(handler)
bootstrap()Changing the span hierarchy also means the example query we showed in a previous post for reading the audit data in S3
needs to change. We already changed the audit processor to ship if span.parent is None or span.parent.is_remote, now
in the query we look for the agent invocations in particular by using gen_ai.operation.name = 'invoke_agent'. This
works with or without the Lambda OTEL data being written.
roots AS ( -- One row per agent run: pydantic-ai's invoke_agent span, identified by -- the GenAI operation rather than by being the parentless span. -- instrument_aws_lambda now roots each trace at the SpanKind.SERVER -- invocation span, so the agent run is a child of it, not the trace root. -- (A caller-side retry would put several invoke_agent spans under one -- invocation; the trace_id join below would then cross them, so that -- case wants each chat tied to its enclosing run instead.) SELECT * FROM spans WHERE list_filter(attributes, x -> x.key = 'gen_ai.operation.name')[1] .value.stringValue = 'invoke_agent'),What validate catches and what it doesn’t
Currently we only run terraform validate, which checks that the HCL and provider config are correct. It does not catch bad naming for Terraform variables, security issues, or misconfigurations that only show up during apply. In the following post we remedy some of this by giving the agent more tools to validate against, and enforcing extra checks such as security baselines.
End state
An agent that takes an English request and leaves a workspace in a validated state. File tools, validate tool, retry chain, and a structured self-report are all in place for posts 4-6 to build on.
Next: Conventions and policy: more tools, same feedback loop